
 Фото: Tobias Keller / Unsplash
Фото: Tobias Keller / UnsplashКлассификация – это крупнейшая задача Машинного обучения (ML), которая ставит своей целью назначить метку класса Наблюдениям (Observation) из предметной области, например, сортировка электронных писем на "спам" и "не спам".
Классификационное прогнозное моделирование
В машинном обучении классификация относится к задаче прогнозного моделирования, когда метка класса прогнозируется для данного примера входных данных.
Примеры проблем классификации:
- Классифицировать рукописный символ как букву или цифру (Handwriting Recognition)
- Учитывая недавнее поведение пользователя, предсказать, откажется он от сервиса сайта или нет (Churn Modeling)
Для классификации требуется обучающий набор с множеством записей, из которых можно учиться.
Модель (Model) будет использовать набор обучающих данных и вычислит, как лучше всего сопоставить примеры входных данных с конкретными метками классов. Таким образом, Тренировочные данные (Train Data) должны быть достаточно репрезентативным для проблемы и иметь достаточно примеров каждой метки класса.
Метки классов часто являются строковыми значениями, например «Спам», «не спам» и будут "конвертированы" в числовые значения, прежде чем будут переданы в алгоритм моделирования. Это называют Кодированием (Encoding), когда каждой метке класса присваивается уникальное целое число, например «Спам» = 0, «не спам» = 1.
Алгоритмы классификационного прогнозного моделирования оцениваются на основе их результатов. Точность измерений (Accuracy) – это популярный показатель, используемый для оценки производительности модели на основе предсказанных меток классов. Точность классификации не идеальна, но это хорошая отправная точка для многих задач классификации.
Вместо меток классов для некоторых задач может потребоваться прогнозирование вероятности "членства" в классе для того или иного наблюдения. Это обеспечивает дополнительную неопределенность в прогнозе, которую затем может использовать программное обеспечение. Популярной диагностикой для оценки предсказанных вероятностей является ROC-кривая (ROC AUC).
Вы можете встретиться с четырьмя основными типами классификации:
- Бинарная классификация (Binary Classification)
- Мультиклассовая классификация (Multi-Class Classification)
- Классификация по нескольким меткам (Multi-Label Classification)
- Несбалансированная классификация (Imbalanced Classification)
Бинарная классификация
Двоичная классификация предполагает два возможных класса меток. Примеры:
- Обнаружение спама в электронной почте (спам или нет)
- Прогнозирование оттока (отток или нет)
- Прогноз конверсии (купит или нет)
Обычно такие задачи включают один класс, который является нормальным состоянием, и другой, который является ненормальным.
Например, «не спам» – это нормальное состояние, а «спам» – ненормальное состояние. Другой пример: «рак не обнаружен» – это нормальное состояние задачи медицинской диагностики, а «рак обнаружен» – это ненормальное состояние. Классу для нормального состояния присваивается метка 0, а классу с ненормальным состоянием – 1.
Модель в этом случае предсказывает распределение вероятностей Бернулли для каждого примера. К примеру, в случае с диагностикой пациентов Алгоритм (Algorithm) сообщит, что пациент № 3049 с вероятностью 85% болен раком.
Популярные алгоритмы, которые можно использовать для двоичной классификации:
- Логистическая регрессия (Logistic Regression)
- Метод K-ближайших соседей (k-Nearest Neighbours)
- Дерево решений (Decision Tree)
- Метод опорных векторов (SVM)
- Наивный байесовский классификатор (Naive Bayes)
Некоторые алгоритмы специально разработаны для двоичной классификации и изначально не поддерживают более двух классов (это логистическая регрессия и метод опорных векторов).
Давайте проанализируем набор данных, чтобы развить интуицию в решении задач двоичной классификации. Мы можем использовать функцию make_blobs() для синтеза игрушечного Датасета (Dataset).
В приведенном ниже примере создается набор данных из 1000 примеров, которые принадлежат одному из двух классов, каждый с двумя входными функциями. Для начала импортируем необходимые для всех типов классификации библиотеки:
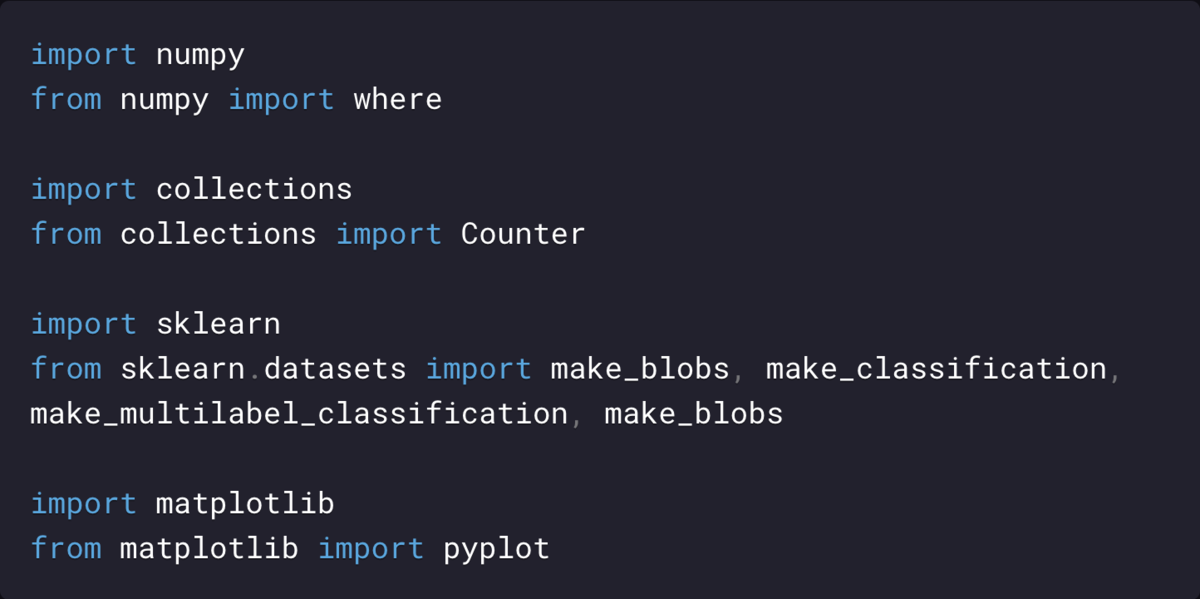
Сначала создаем набор данных, состоящий из 1000 примеров, разделенных на Предикторы (Predictor Variable) X и Целевую переменную (Target Variable) y.
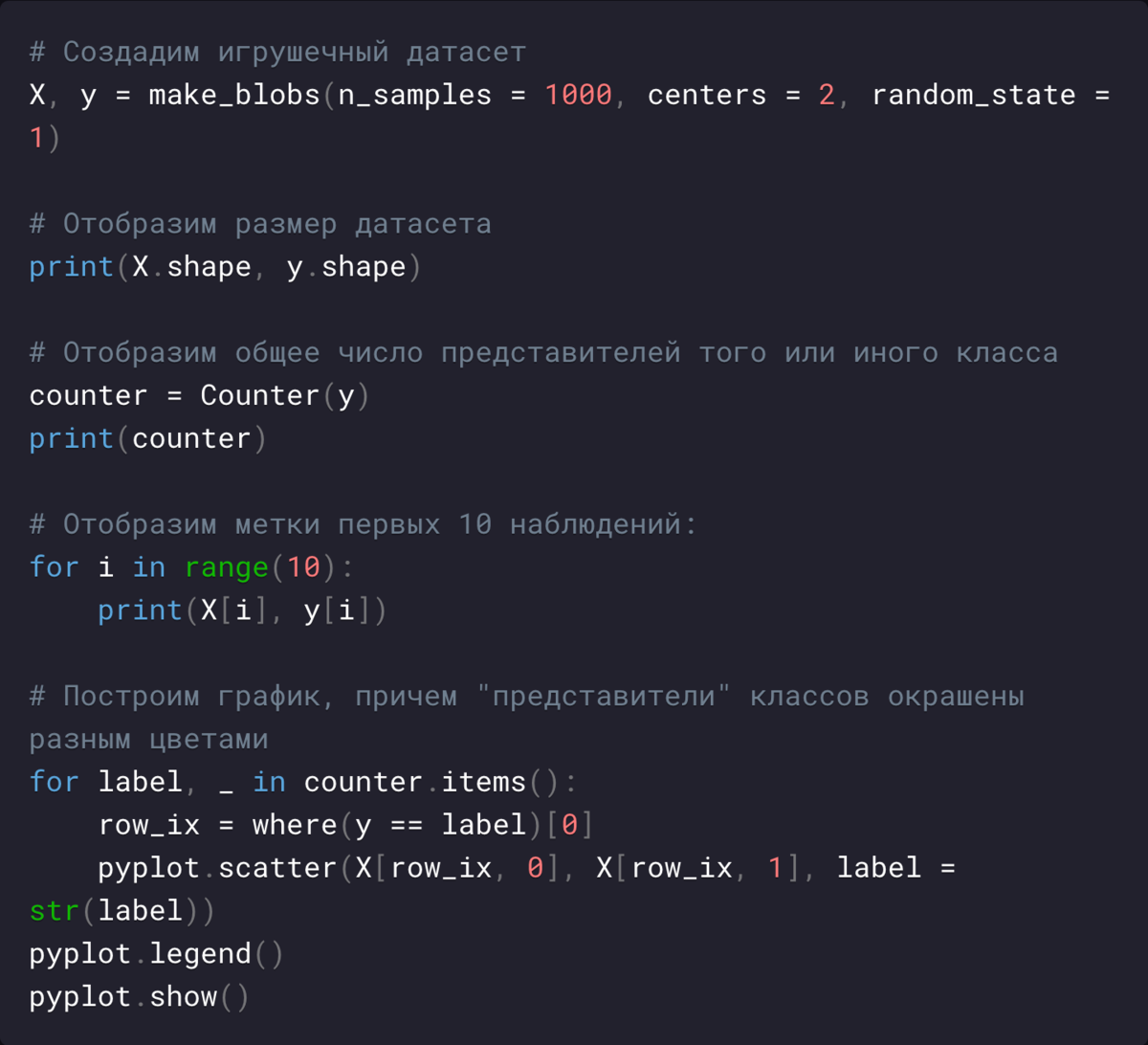
Наконец создается Точечная диаграмма (Scatterplot), а точки окрашиваются в соответствии со значением их класса.
Обратите внимание: Как работает АЭС? Простыми словами о сложном.
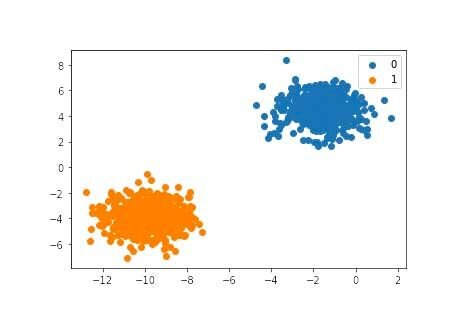
Мы видим два различных кластера, которые легко различить: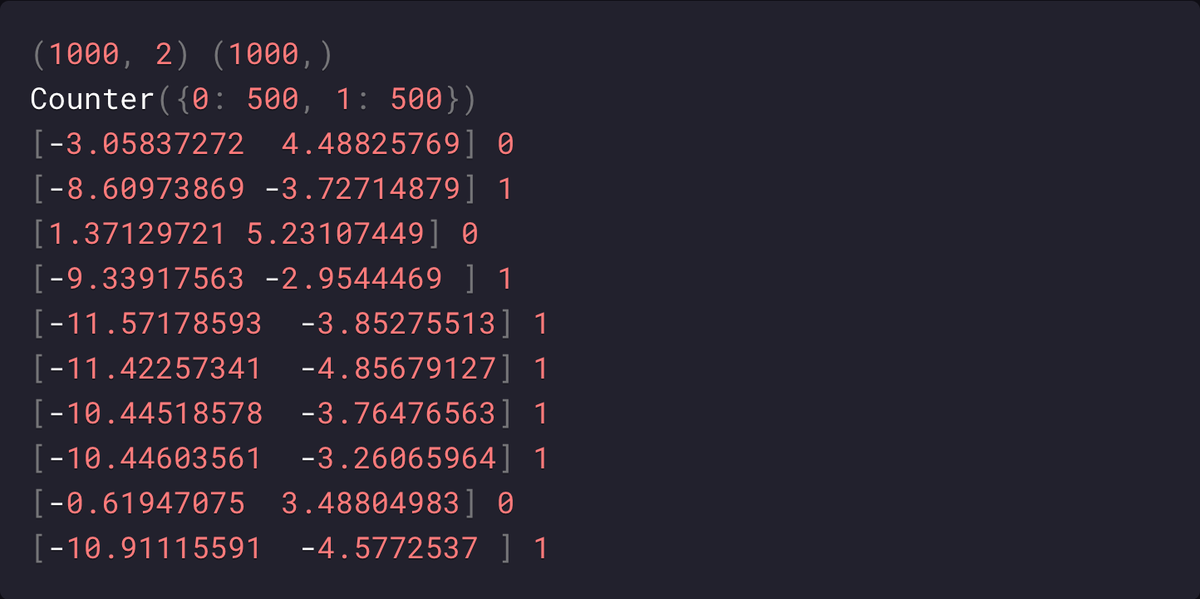
Мультиклассовая классификация
Мультиклассовая классификация предполагает, что классов более двух. Примеры включают:
- Классификация лиц
- Классификация видов растений
- Оптическое распознавание символов
В отличие от бинарной классификации, мультиклассовая классификация не имеет понятия нормальных и аномальных исходов. Вместо этого примеры классифицируются как принадлежащие к одному из ряда известных классов.
Для некоторых задач количество меток классов может быть очень большим. Например, модель может предсказать фотографию как принадлежащую одному из тысяч или десятков тысяч лиц в системе распознавания лиц.
Обычно такую задачу отрабатывают с помощью модели, которая прогнозирует Распределение вероятностей Мультинулли (Multinoulli Probability Distribution) для каждого примера.
Распределение Мультинулли – это дискретное распределение вероятностей, которое охватывает случай, когда событие будет иметь категориальный исход, например K в {1, 2, 3,…, K}. Для классификации это означает, что модель предсказывает вероятность принадлежности примера к той или иной метке класса.
Многие алгоритмы, используемые для двоичной классификации, могут использоваться и для мультиклассовой:
- Метод k-ближайших соседей
- Дерево решени
- Наивный байесовский классификатор
- Случайный лес (Random Forest)
- Градиентный бустинг (Gradient Boosting)
Такая классификация использует бинарную для каждого класса по сравнению со всеми другими (one-vs-rest) или одного для каждой пары классов (one-vs-one):
- "Один против остальных" (one-vs-rest): создаем одну модель бинарной классификации для каждого класса по сравнению со всеми другими классами
- "Один против одного" (one-vs-one): создаем одну модель бинарной классификации для каждой пары классов
Алгоритмы мультиклассовой классификации:
- Логистическая регрессия
- Машина опорных векторов
Давайте подробнее рассмотрим набор данных, чтобы развить интуицию для решения подобных задач. Мы использовать функцию make_blobs() для синтеза набора:
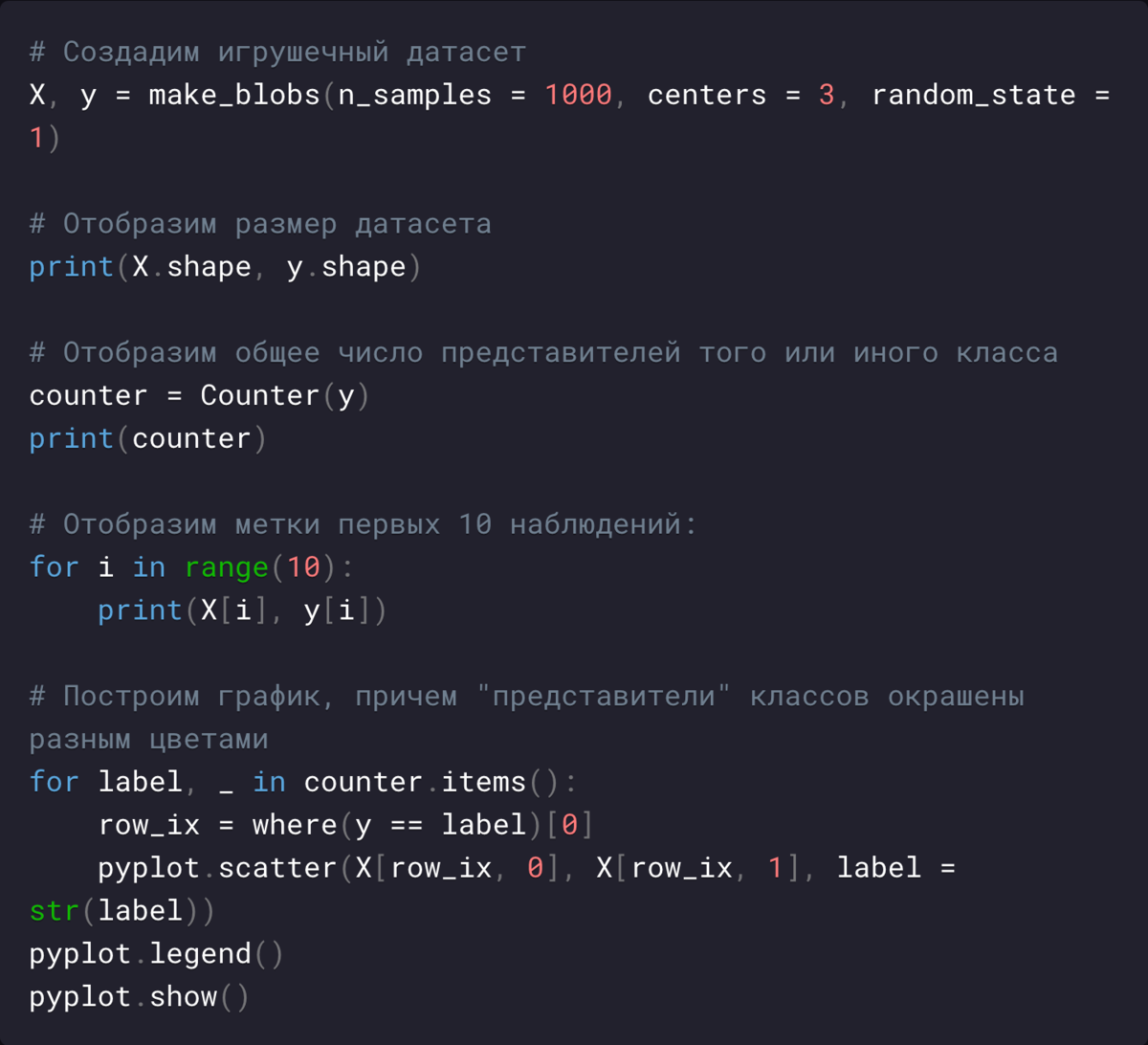
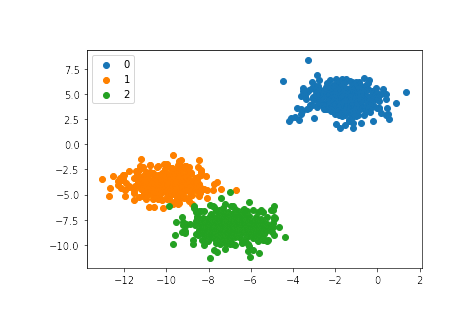
В приведенном примере создается набор из 1000 примеров, которые принадлежат одному из трех классов. Наконец, создается диаграмма, а точки окрашиваются в соответствии со значением их класса:
Мы можем видеть три различных кластера, которые легко различить.
Классификация по нескольким меткам
Такая классификация предполагает, что имеется две или более метки классов.
Рассмотрим пример классификации объектов на фотографии, причем изображение может иметь несколько объектов, таких как «велосипед», «яблоко», «человек» и т.д. Это не похоже на двоичную и мультиклассовую классификации, где для каждого примера прогнозируется одна метка класса.
По сути, это модель, которая делает несколько прогнозов двоичной классификации для каждого примера.
Алгоритмы классификации, используемые для двоичной или мультиклассовой классификации, не могут использоваться напрямую для классификации по нескольким меткам. Могут использоваться специализированные версии стандартных алгоритмов:
- Деревья решений с несколькими ярлыками
- Случайные леса с несколькими ярлыками
- Градиентный бустинг с несколькими ярлыками
Затем давайте более подробно рассмотрим набор данных, чтобы развить интуицию для такого типа задач.
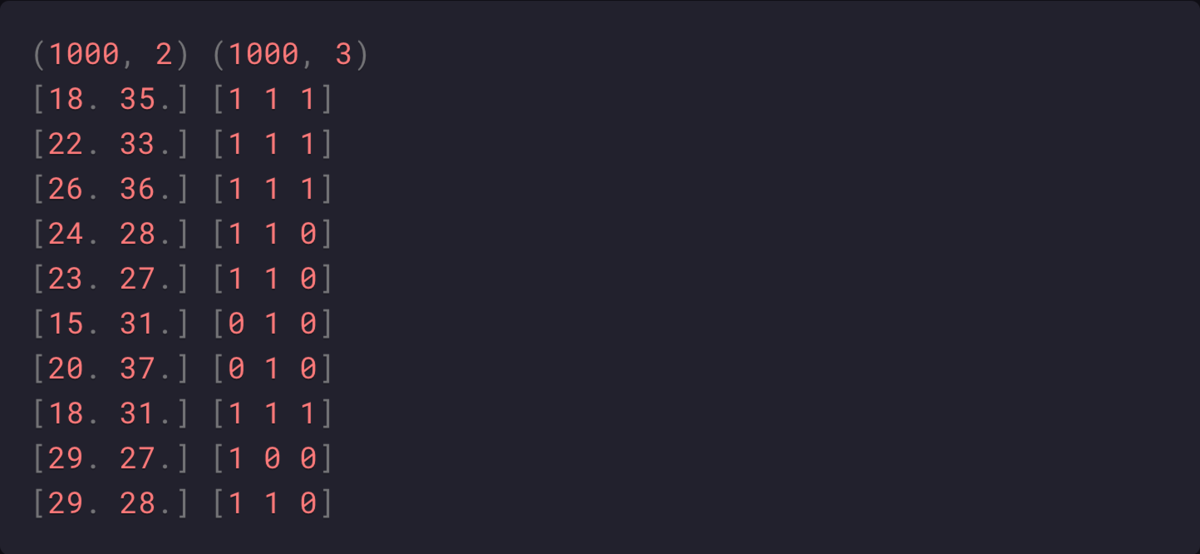
Мы используем функцию make_multilabel_classification() для синтеза набора данных с несколькими метками:

В приведенном ниже примере создается набор данных из 1000 примеров, каждый с двумя входными функциями. Есть три класса, каждый из которых может иметь одну из двух меток (0 или 1).
Несбалансированная классификация
Несбалансированная классификация относится к задачам классификации, в которых количество примеров в классах распределяется неравномерно.
Как правило, такие задачи представляют собой задачи двоичной классификации, где большинство примеров в наборе обучающих данных относятся к нормальному классу, а меньшая часть примеров относится к ненормальному классу.
Примеры:
- Обнаружение мошенничества (Fraud Detection)
- Обнаружение выбросов
- Медицинские диагностические тесты
Эти проблемы моделируются как задачи бинарной классификации, хотя могут потребоваться специальные методы.
Примеры алгоритмов:
- Случайное недосэмплирование (Random Undersampling)
- Алгоритм SMOTE (SMOTE Oversampling)
Могут использоваться специализированные алгоритмы моделирования, которые уделяют больше внимания классу меньшинства при подгонке модели к набору обучающих данных, например, Чувствительные к стоимости алгоритмы (Cost-Sensitive Algorithm).
Примеры:
- Логистическая регрессия с учетом затрат
- Деревья принятия решений с учетом затрат
- Чувствительные к стоимости машины опорных векторов
Наконец, могут потребоваться альтернативные показатели производительности, поскольку точности классификации может вводить в заблуждение.
Примеры включают:
- Точность (Precision)
- Отзыв (Recall)
- Критерий F1 (F1 Score)
Давайте подробно рассмотрим набор данных, чтобы развить интуицию в отношении несбалансированных проблем классификации.
Мы используем функцию make_classification() для синтеза набора данных:
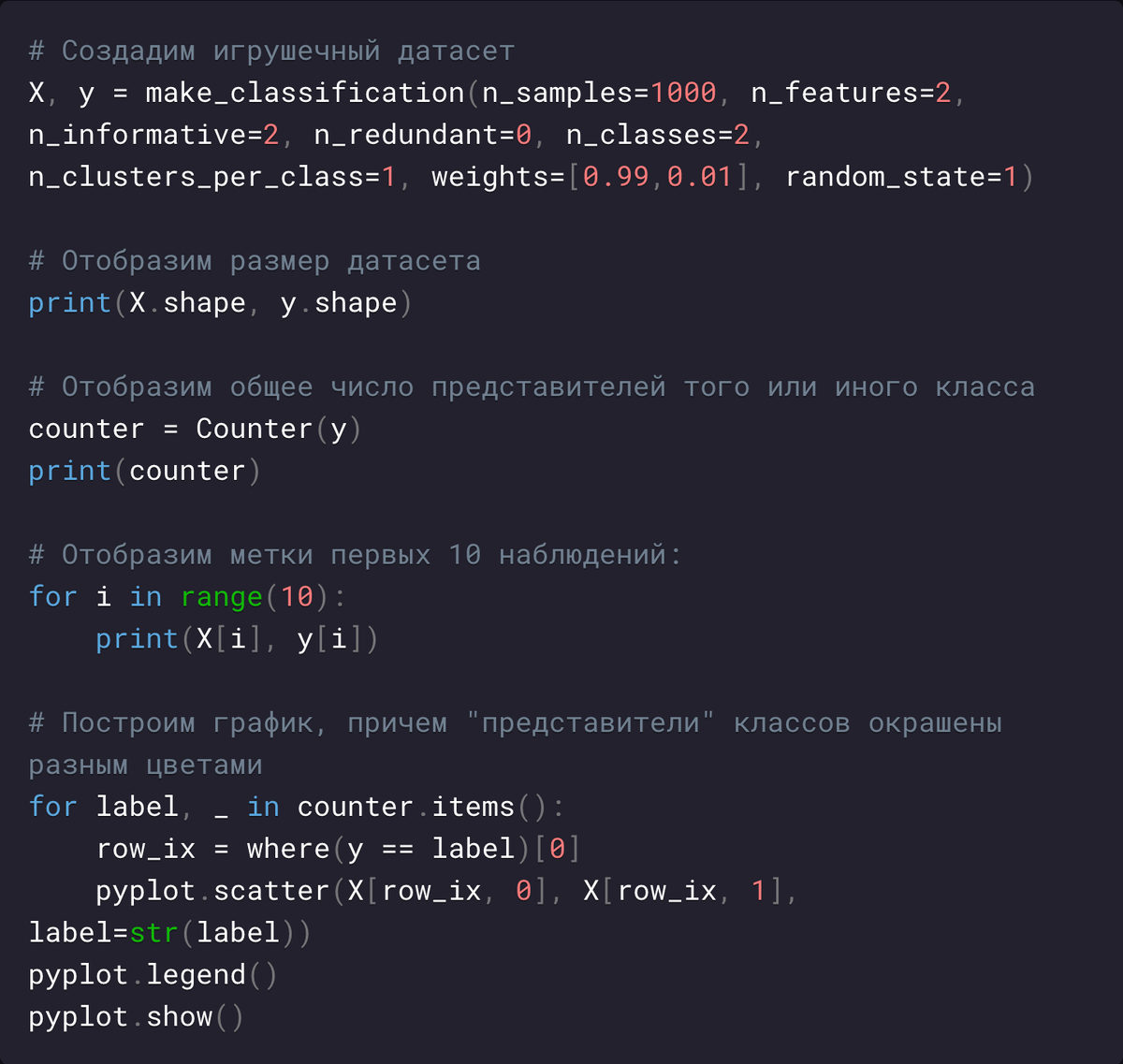
В приведенном ниже примере создается набор данных из 1000 примеров, которые принадлежат одному из двух классов, каждый с двумя предикторами:
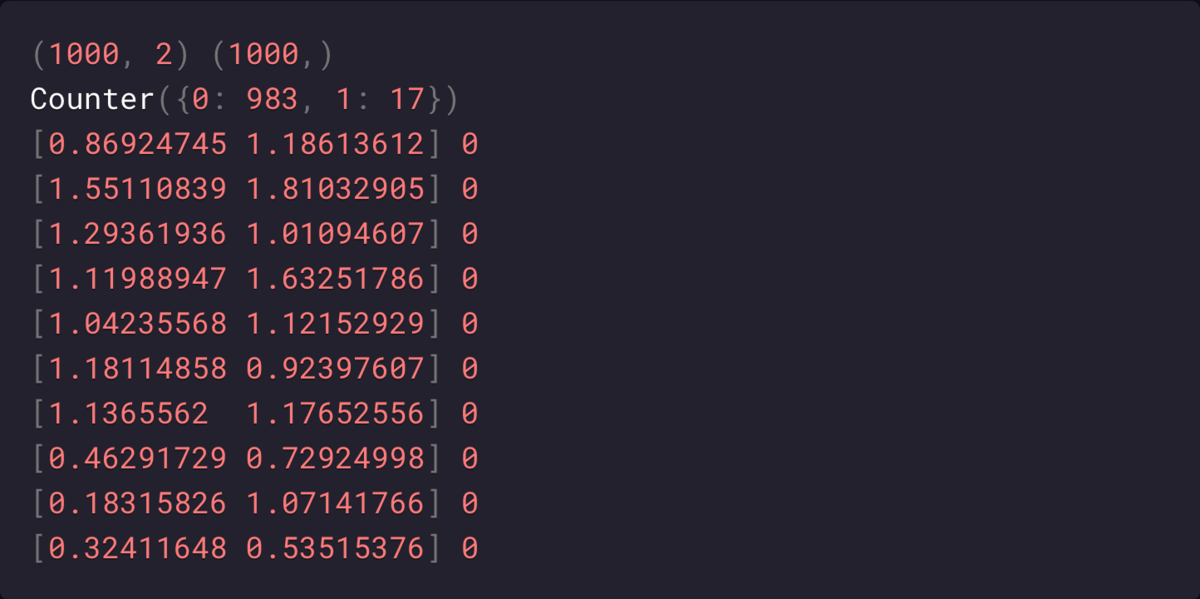
Для набора создается диаграмма рассеяния, а точки окрашиваются в соответствии со значением их класса:
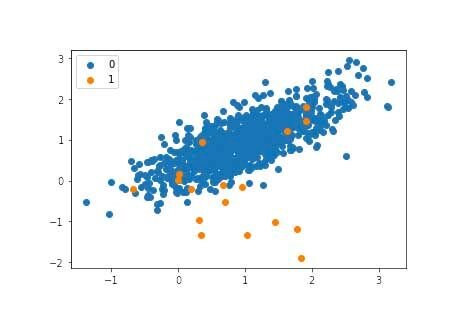
Мы можем видеть один основной кластер для примеров, принадлежащих классу 0, и несколько разрозненных примеров, принадлежащих классу 1. Интуиция подсказывает, что моделировать наборы данных с этим свойством несбалансированных меток классов сложнее.
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Jason Brownlee
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курсы на Udemy.
Еще по теме здесь: Новости науки и техники.
Источник: Classification в Машинном обучении простыми словами.