

Классификация — одна из ключевых и наиболее распространённых задач в машинном обучении. Её цель — присвоить метку класса каждому наблюдению (например, определить, является ли письмо спамом или нет). По сути, это процесс сортировки данных по заранее определённым категориям на основе их характеристик.
Что такое классификационное прогнозное моделирование?
В контексте машинного обучения классификация — это тип прогнозного моделирования, при котором для входных данных предсказывается категориальная метка. Например, алгоритм может определять, какая буква или цифра изображена на рукописном тексте, или прогнозировать, останется ли пользователь сервиса или откажется от него (так называемое моделирование оттока).
Для обучения классификатора необходим набор данных с множеством примеров, уже размеченных по классам. Модель анализирует эти данные, выявляет закономерности и учится сопоставлять новые входные данные с соответствующими метками. Важно, чтобы обучающая выборка была репрезентативной и содержала достаточное количество примеров для каждого класса.
Поскольку большинство алгоритмов машинного обучения работают с числами, текстовые метки (например, «спам» / «не спам») обычно преобразуются в числовые значения с помощью кодирования. Например, «спам» может кодироваться как 0, а «не спам» — как 1.
Эффективность классификаторов часто оценивают по точности — доле правильно предсказанных меток. Хотя точность — не идеальный показатель, она служит хорошей отправной точкой. В некоторых задачах важнее предсказать вероятность принадлежности к классу, а не просто метку. Для оценки вероятностных прогнозов используют, например, ROC-кривую (ROC AUC).
Выделяют четыре основных типа задач классификации:
- Бинарная классификация
- Мультиклассовая классификация
- Многометочная классификация
- Несбалансированная классификация
Бинарная классификация
Это самый простой тип, где есть всего два возможных класса. Примеры: фильтрация спама (спам / не спам), прогноз оттока клиентов (уйдёт / останется) или предсказание, совершит ли пользователь покупку (да / нет). Обычно один класс представляет нормальное состояние (например, «не спам», метка 0), а другой — аномальное («спам», метка 1).
Модель бинарной классификации часто предсказывает вероятность принадлежности к положительному классу (например, вероятность того, что пациент болен). Для этого используются алгоритмы вроде логистической регрессии, метода k-ближайших соседей, деревьев решений, метода опорных векторов или наивного байесовского классификатора. Некоторые из них (логистическая регрессия, SVM) изначально предназначены только для двух классов.
Для наглядности можно создать синтетический датасет с двумя чёткими кластерами точек, соответствующих разным классам. Визуализация помогает понять, как алгоритм разделяет данные.
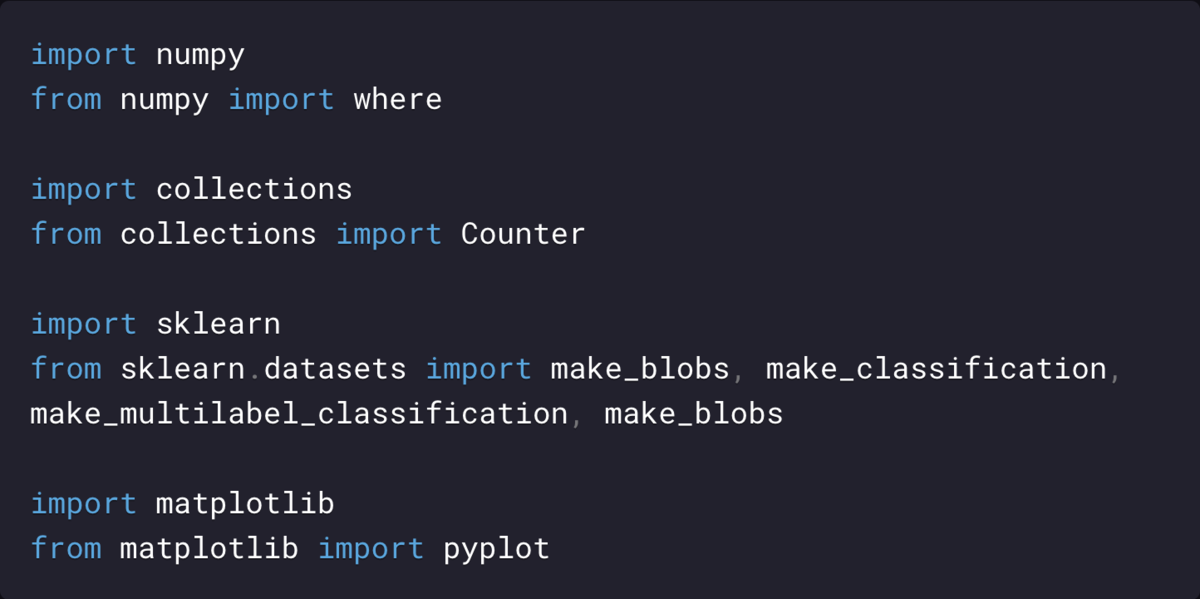
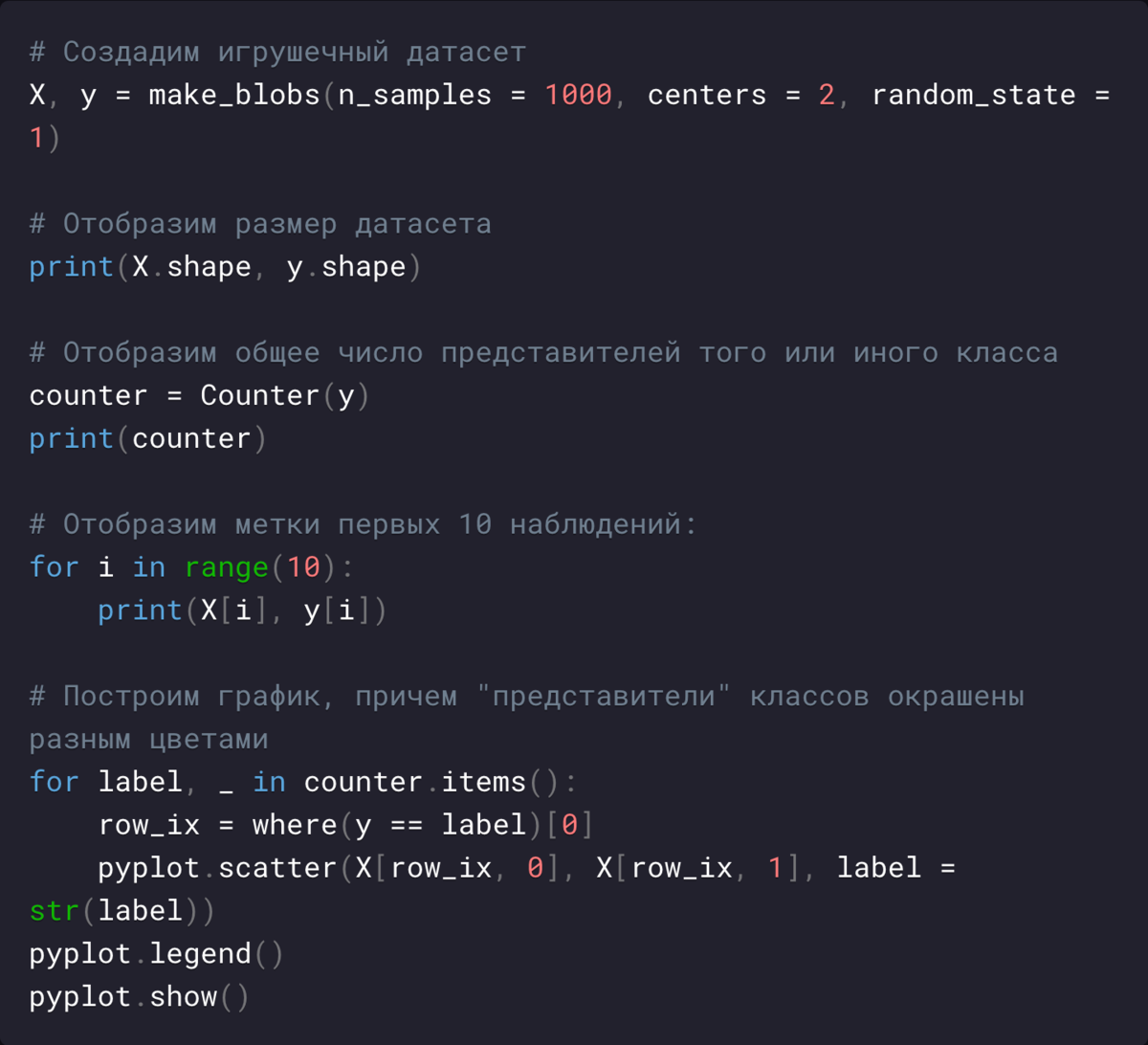
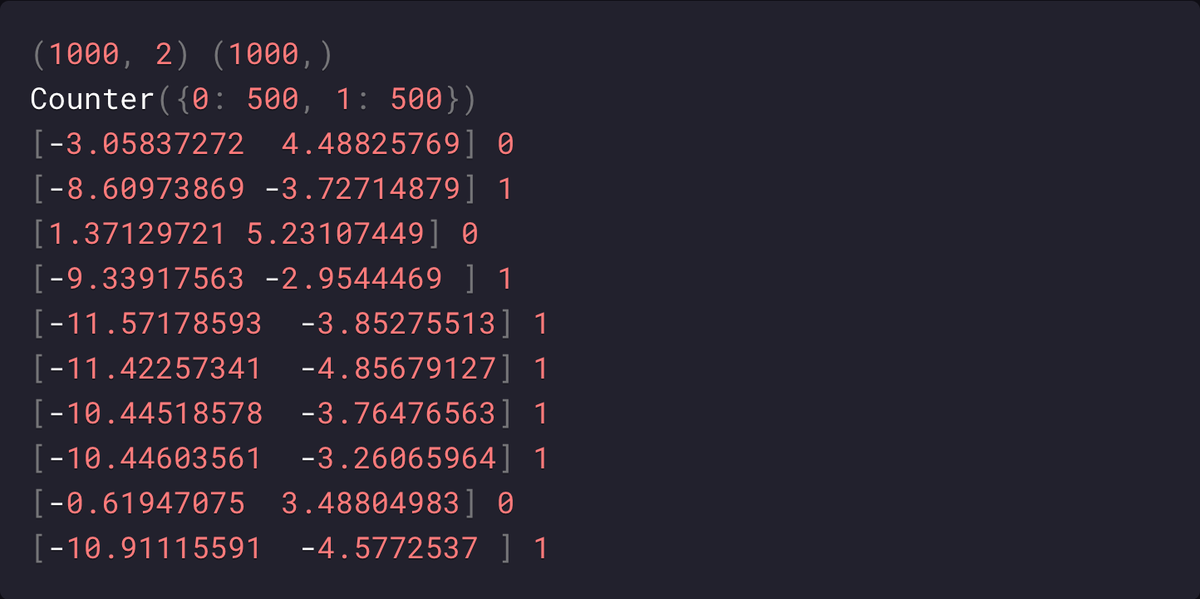
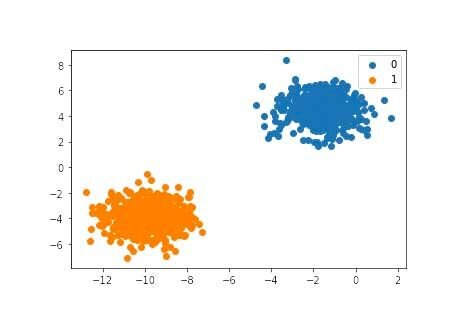
Мультиклассовая классификация
Здесь классов больше двух. Примеры: распознавание лиц (какому из тысяч человек принадлежит фото), классификация видов растений или оптическое распознавание символов. В отличие от бинарной классификации, здесь нет понятия «нормального» состояния — объект просто относится к одному из множества классов.
Модель обычно предсказывает распределение вероятностей по всем классам (распределение Мультинулли), указывая, насколько вероятна принадлежность объекта к каждому из них. Многие алгоритмы бинарной классификации можно адаптировать для мультиклассовых задач, используя стратегии «один против всех» (one-vs-rest) или «один против одного» (one-vs-one). Также популярны алгоритмы вроде случайного леса или градиентного бустинга.
Синтетический датасет с тремя классами наглядно демонстрирует, как данные могут группироваться в несколько отдельных кластеров.
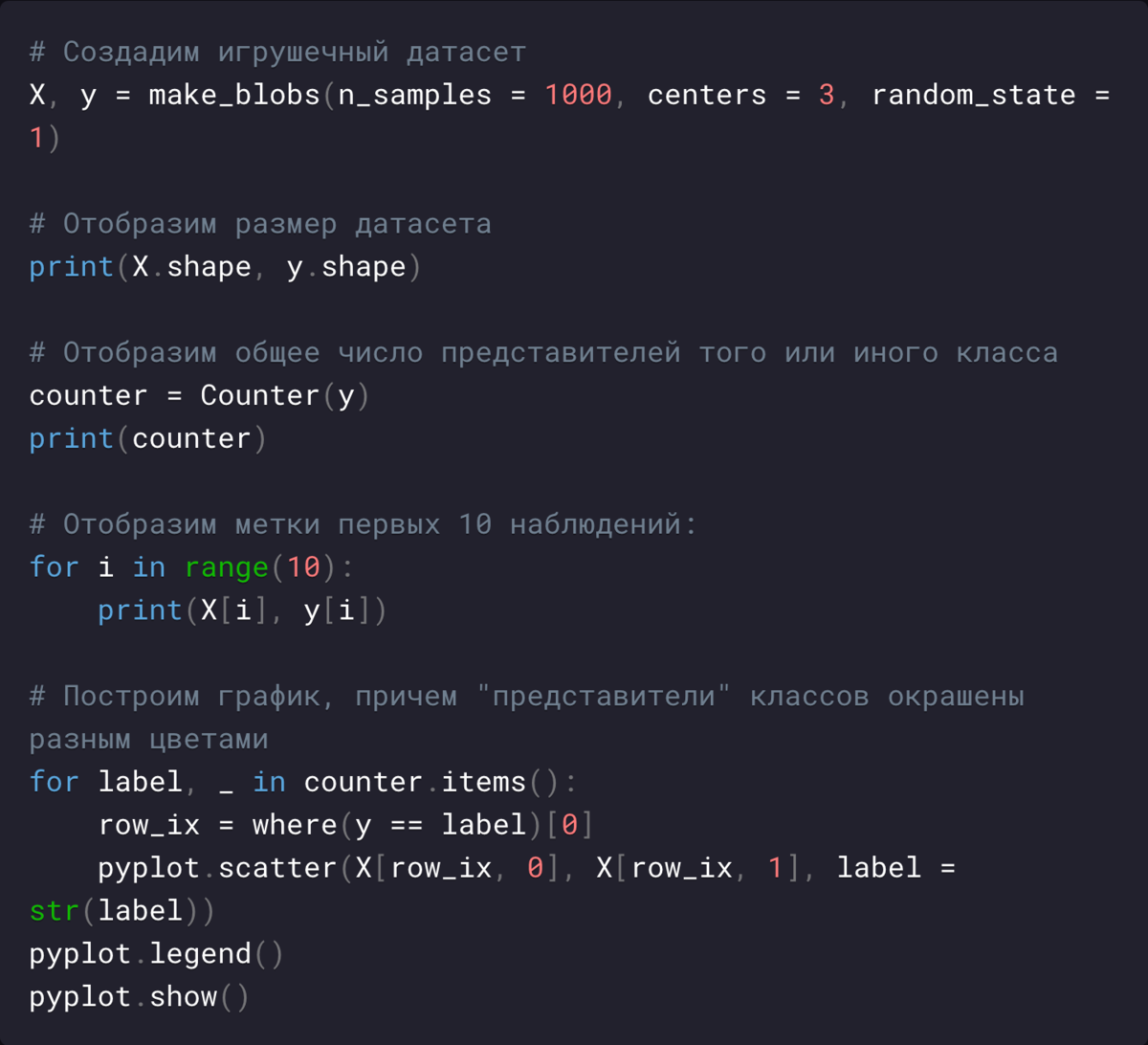
Многометочная классификация
В этом случае один объект может одновременно принадлежать к нескольким классам. Классический пример — анализ изображения, на котором могут присутствовать разные объекты: «велосипед», «яблоко», «человек» и т.д. По сути, это несколько задач бинарной классификации для одного примера.
Стандартные алгоритмы здесь не подходят — требуются их специализированные версии, например, деревья решений или случайные леса с поддержкой нескольких меток. Синтетические данные для такой задачи могут иметь несколько бинарных меток для каждого наблюдения.
Несбалансированная классификация
Особый случай, когда примеры в классах распределены неравномерно: один класс (часто «нормальный») представлен значительно больше, чем другой («аномальный»). Такие задачи типичны для обнаружения мошенничества, диагностики редких заболеваний или выявления выбросов.
Обычные алгоритмы здесь склонны игнорировать класс меньшинства, поэтому требуются специальные методы: сэмплирование (например, SMOTE для увеличения числа примеров миноритарного класса или недосэмплирование мажоритарного), cost-sensitive алгоритмы (учитывающие большую «стоимость» ошибки для редкого класса) или альтернативные метрики оценки (точность, полнота, F1-мера вместо общей точности).
Визуализация несбалансированного датасета показывает один плотный кластер для основного класса и немного разрозненных точек для редкого класса, что иллюстрирует сложность задачи.
Ноутбук с примерами кода, не требующий дополнительной настройки, доступен для скачивания.
Автор оригинальной статьи: Jason Brownlee
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курсы на Udemy.
Еще по теме здесь: Новости науки и техники.
Источник: Classification в Машинном обучении простыми словами.