
Этот список ключевых концепций составлен на основе многолетнего опыта и педагогической практики доктора Бенджамина Оби Тайо. Комментарии автора статьи [приведены в квадратных скобках]. Продолжаем разбирать фундаментальные темы для начинающих специалистов в области данных.
11. Обучение без учителя (Unsupervised Learning)
В отличие от обучения с учителем, здесь мы работаем с немаркированными данными, структура которых изначально неизвестна. Основная цель — исследовать и обнаружить скрытые закономерности, группировки или аномалии в данных без заранее заданной целевой переменной. Классический пример — алгоритм K-means, который автоматически разбивает данные на кластеры.

На изображении показана визуализация работы алгоритма K-means с четырьмя кластерами (K=4).
[Алгоритм итеративно определяет центры кластеров и относит каждую точку данных к ближайшему центру, оптимизируя компактность групп.]
12. Обучение с подкреплением (Reinforcement Learning)
Этот подход имитирует процесс обучения через взаимодействие с окружающей средой. Агент (система) совершает действия и получает обратную связь в виде «вознаграждения» или «штрафа». Цель — выучить стратегию (последовательность действий), которая максимизирует совокупное вознаграждение в долгосрочной перспективе. В отличие от обучения с учителем, здесь нет готовых правильных ответов — агент учится на собственном опыте.
[Яркий пример — система управления посадкой ракетной ступени Falcon от SpaceX. Модель, обучаясь с подкреплением, «подруливает» двигателями, чтобы удержать ступень в вертикальном положении, получая вознаграждение за успешную посадку в заданной точке.]

Кадр из видео компании SpaceX, иллюстрирующий сложную задачу, решаемую с помощью обучения с подкреплением.
13. Параметры модели и гиперпараметры
Понимание разницы между этими двумя типами параметров критически важно для построения эффективных моделей.
Параметры модели — это внутренние переменные, которые модель обучается определять на основе данных. Например, в линейной регрессии для предсказания цены дома: Цена = a + b * (возраст) + c * (площадь). Коэффициенты a, b и c — это параметры, которые подбираются в процессе обучения.
Гиперпараметры — это настраиваемые «ручки», которые задаются до начала обучения и управляют самим процессом обучения. Они не выводятся из данных. Пример из библиотеки scikit-learn: KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski'). Здесь n_neighbors — гиперпараметр. Подбор оптимальных гиперпараметров — одна из ключевых задач дата-сайентиста, напрямую влияющая на качество итоговой модели.
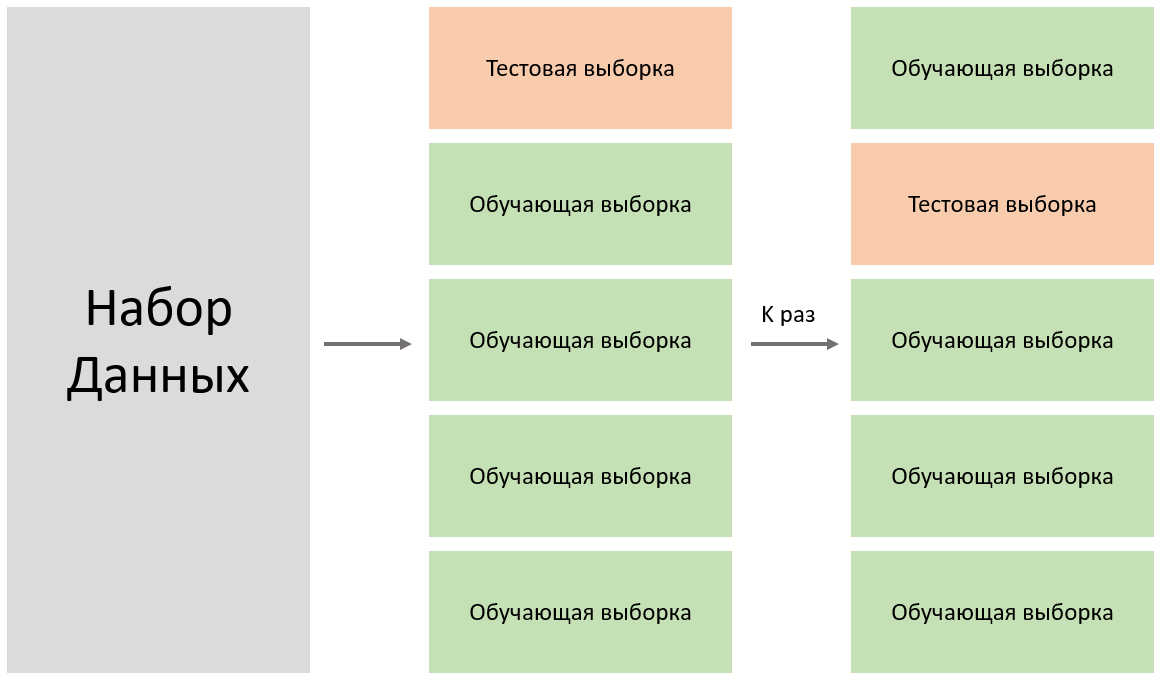
14. Перекрестная проверка (Cross-validation)
Это мощный метод для надежной оценки того, насколько хорошо модель будет обобщаться на новые, невиданные данные. Он помогает избежать переобучения на конкретном разбиении данных и зафиксировать возможные смещения.
При k-кратной перекрестной проверке исходный набор данных случайным образом разбивается на k равных частей (фолдов). Модель обучается k раз: каждый раз на (k-1) фолдах, а на оставшемся одном фолде — тестируется. Итоговая оценка качества (например, средняя точность) вычисляется как среднее по всем k циклам. Это дает более стабильную и объективную метрику, чем простое разбиение на тренировочную и тестовую выборку один раз.
15. Компромисс смещения и разброса (Bias-Variance Tradeoff)
Это фундаментальная дилемма машинного обучения, описывающая два источника ошибок прогнозирующей модели.
- Смещение (Bias) — это ошибка, вызванная слишком упрощенными предположениями модели. Высокое смещение приводит к недообучению: модель не улавливает важные закономерности в данных, делая систематически неточные прогнозы даже на тренировочных данных.
- Разброс (Variance) — это ошибка, вызванная чрезмерной чувствительностью модели к шуму в тренировочных данных. Высокий разброс приводит к переобучению: модель идеально запоминает тренировочные данные (включая их случайные колебания), но плохо работает на новых данных.
Задача специалиста — найти «золотую середину», балансируя между слишком простой моделью (высокое смещение) и слишком сложной (высокий разброс).
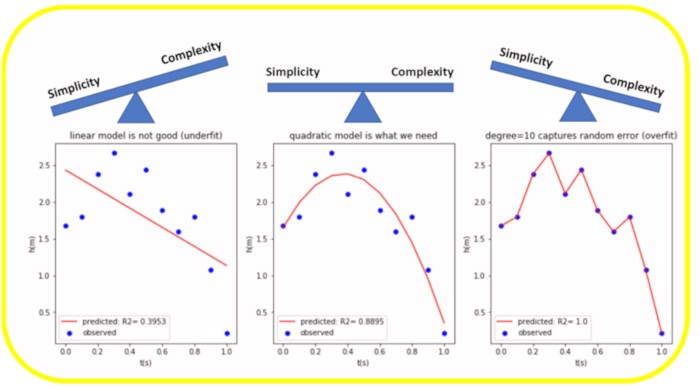
Иллюстрация компромисса: слева — высокая ошибка из-за смещения, справа — из-за разброса, в центре — оптимальный баланс. Изображение Benjamin O. Tayo.
16. Метрики оценки модели
Выбор правильной метрики для оценки модели так же важен, как и построение самой модели. Метрики зависят от типа задачи:
- Для регрессии (предсказание непрерывного значения): R² (коэффициент детерминации), MSE (среднеквадратичная ошибка), MAE (средняя абсолютная ошибка).
- Для классификации (предсказание категории): Accuracy (точность), Precision (точность), Recall (полнота), F1-мера (гармоническое среднее Precision и Recall), AUC-ROC (площадь под кривой ошибок).
17. Количественная оценка неопределенности
Хорошая модель должна не только делать прогнозы, но и оценивать степень уверенности в них. Ключевой метрикой здесь часто выступает R² (коэффициент детерминации). Он показывает, какая доля изменчивости целевой переменной объясняется признаками модели. R² = 1 означает идеальное объяснение, R² = 0 — что модель не лучше, чем простое предсказание средним значением.
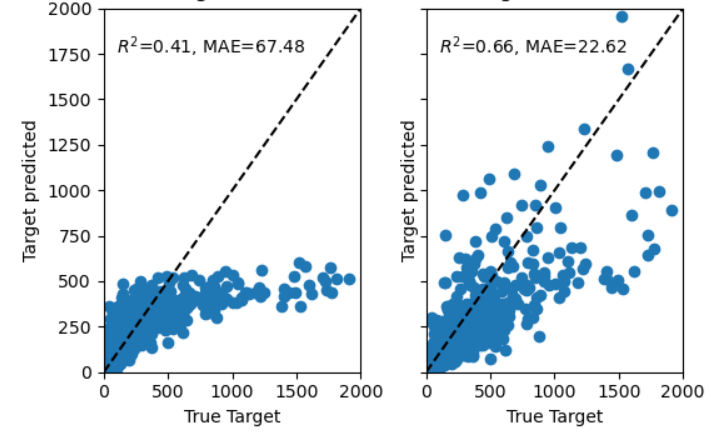
[На примере из библиотеки sklearn видно: график справа имеет более высокий R², так как точки данных лучше ложатся на линию регрессии. На графике слева зависимость между признаками и целевой переменной носит более случайный характер, что отражается в низком R².]
18. Математический фундамент
a) Математический анализ (Calculus): Необходим для понимания процессов оптимизации, лежащих в основе обучения моделей, особенно нейронных сетей.
- Функции многих переменных, частные производные, градиенты.
- Активационные функции: сигмоида, ReLU, softmax.
- Функции потерь (cost functions) и их минимизация.
б) Линейная алгебра: Самый важный математический инструмент в Data Science. Данные представляются в виде векторов и матриц.
- Векторы, матрицы, операции над ними (транспонирование, умножение).
- Собственные значения и векторы (ключ для PCA — уменьшения размерности).
- Нормы векторов, скалярное произведение.
в) Методы оптимизации: Алгоритмы поиска наилучших параметров модели.
- Градиентный спуск и его вариации (стохастический, mini-batch).
- Функция правдоподобия, функция ошибки.
19. Статистика и теория вероятностей
Статистика — это язык данных. Она используется на всех этапах: от первичного анализа до валидации модели.
- Описательная статистика: среднее, медиана, мода, дисперсия, корреляция.
- Распределения: нормальное, биномиальное, Пуассона.
- Статистические тесты: p-value, A/B-тестирование.
- Байесовские методы: теорема Байеса (основа для многих алгоритмов классификации и оценки точности/полноты).
- Оценка ошибок: MSE, R².
- Моделирование: Метод Монте-Карло.
20. Инструменты для эффективной работы
Успешный дата-сайентист — это не только теоретик, но и эффективный практик, владеющий современным стеком инструментов для организации работы.
- Операционные системы и среда: GNU/Linux — стандарт для продакшн-сред, Jupyter Notebook/Lab — для исследования и прототипирования.
- Контроль версий: Git и GitHub/GitLab — обязательные инструменты для управления кодом и коллаборации.
- Контроль версий данных (Data Version Control): DVC — аналог Git для датасетов и моделей, позволяющий отслеживать изменения в данных.
- Развертывание моделей (MLOps): Flask/Django — для создания API-интерфейсов модели, Docker — для упаковки модели и её зависимостей в контейнер для стабильного запуска в любой среде.
Стоит еще зайти сюда: Новости науки и техники.
Источник статьи: Топ-20 обязательных концепций Data Science для начинающих (Часть 2).