
Эта статья представляет собой сборник ключевых вопросов и концепций из области Data Science. Она поможет освежить и систематизировать знания об основных технологиях и подходах, используемых в работе с данными.

1. SQL для аналитики данных
SQL — фундаментальный язык для работы с базами данных. Рассмотрим несколько типовых аналитических запросов.
Пример 1: Поиск сотрудников с зарплатой выше, чем у руководителя. Для этого используется самосоединение (self-join) таблицы, чтобы сравнить зарплату сотрудника (a) с зарплатой его начальника (b).
SELECT * FROM employee AS a, employee AS b WHERE b.id = a.chief_id AND a.salary > b.salary;
Пример 2: Поиск второй по величине зарплаты. Здесь применяется подзапрос для нахождения максимального значения, а затем выбирается максимальное из оставшихся.
SELECT MAX(salary) AS NextMaxSalary FROM employee WHERE SALARY != (SELECT MAX(salary) FROM employee);
Пример 3: Нумерация строк внутри департамента. Оконная функция ROW_NUMBER() с предложением PARTITION BY позволяет присвоить порядковый номер строкам в каждой группе (департаменте), отсортированным по зарплате.
SELECT ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary) AS salary_num FROM employee;
2. Основы математической статистики
Статистика предоставляет инструменты для описания и анализа данных.
Математическое ожидание
Математическое ожидание (M[x]) — это средневзвешенное значение случайной величины, где весами выступают вероятности. Например, для величин 1, 3, 4, 7 с вероятностями 0.1, 0.1, 0.2, 0.3 расчет будет: M[x] = 1*0.1 + 3*0.1 + 4*0.2 + 7*0.3 = 3.3.
Медиана
Медиана — это значение, которое делит упорядоченный набор данных пополам (квантиль 0.5). Если количество элементов четное, медиана равна среднему арифметическому двух центральных значений.
Квантиль
Квантиль — это пороговое значение, ниже которого лежит определенная доля данных. Например, квантиль 0.25 (первый квартиль) показывает значение, меньше которого находится 25% наблюдений.
Мода
Мода — это наиболее часто встречающееся значение в наборе данных. В ряду [4, 4, 3, 5] мода равна 4.
Бимодальное распределение
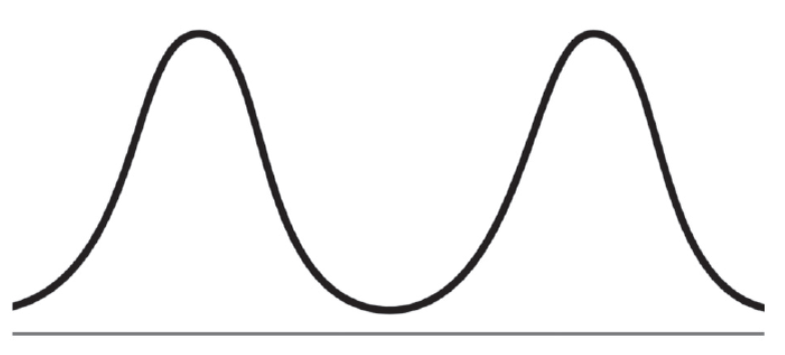
Бимодальное распределение имеет два выраженных пика (моды). В таких случаях общие средние показатели могут вводить в заблуждение. Эффективнее разделить данные на однородные подгруппы и анализировать их отдельно.
Дисперсия и СКО
Дисперсия (D(X)) измеряет разброс значений вокруг среднего. Формула: D(X) = M[(X - M(X))^2].
Среднеквадратическое отклонение (СКО) — это квадратный корень из дисперсии. Оно показывает, насколько в среднем значения отклоняются от математического ожидания, и выражено в тех же единицах, что и исходные данные.
Интерквантильный размах
Интерквантильный размах (IQR) — это разница между третьим (Q3, 0.75) и первым (Q1, 0.25) квартилями: IQR = X_0.75 - X_0.25. Он характеризует разброс средней части данных и менее чувствителен к выбросам, чем дисперсия.
3. Основы теории вероятностей
Теория вероятностей формализует понятие случайности и лежит в основе статистических выводов.
Пересечение событий (∩)
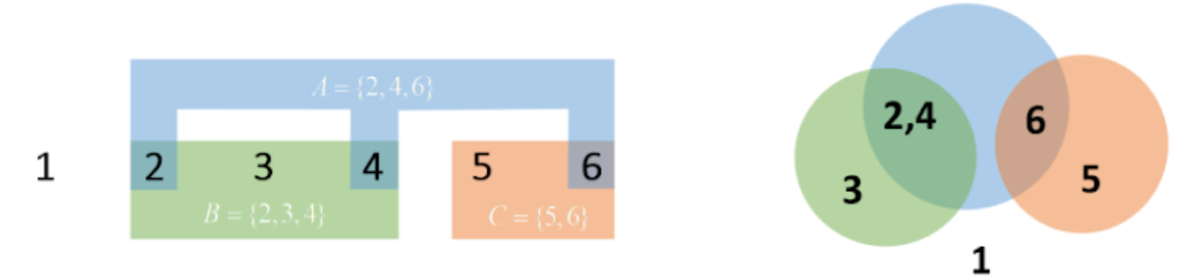
Пересечение событий A и B (A ∩ B) включает исходы, которые принадлежат одновременно и A, и B. Пример: для пространства {1,2,3,4,5,6}, событий A={2,4,6} и B={2,3,4}, пересечение A ∩ B = {2,4}.
Объединение событий (∪)
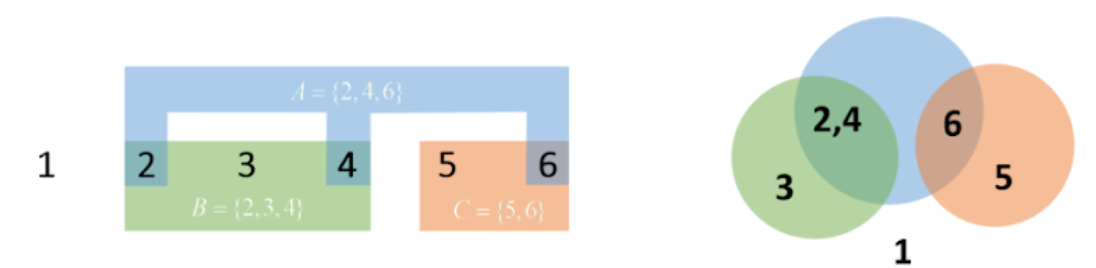
Объединение событий A и B (A ∪ B) включает все исходы, которые принадлежат хотя бы одному из событий. Для тех же A и B объединение A ∪ B = {2,3,4,6}.
Условная вероятность
Вероятность события A при условии, что событие B уже произошло, вычисляется по формуле: P(A|B) = P(A ∩ B) / P(B), где P(B) > 0.
Взаимоисключающие события и полная группа
События являются взаимоисключающими, если они не могут произойти одновременно (их пересечение пусто). Полная группа событий — это набор взаимоисключающих событий, объединение которых дает все пространство исходов (сумма их вероятностей равна 1).
Теорема Байеса
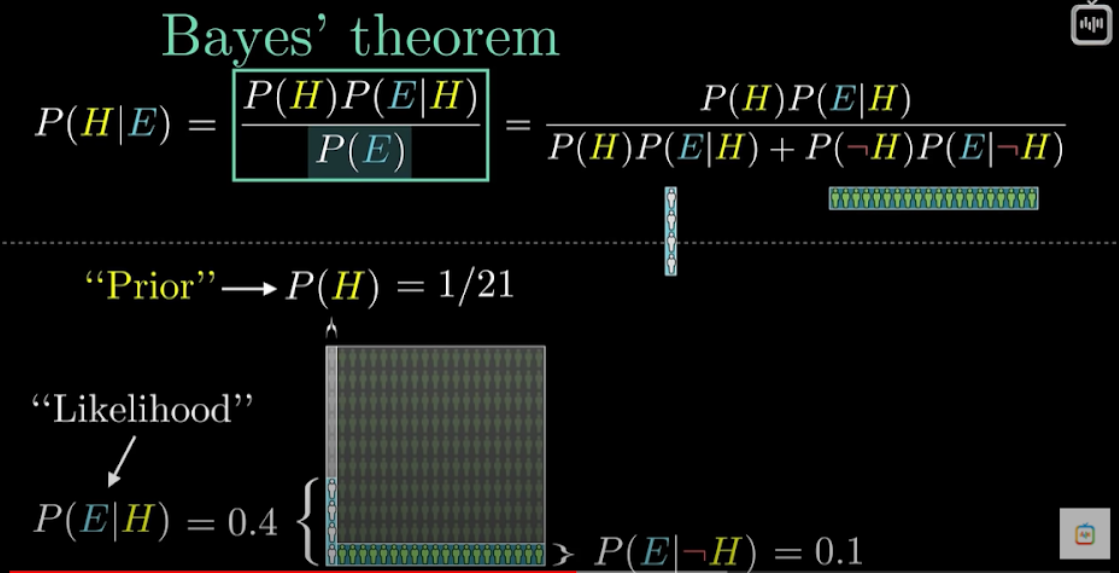
Теорема Байеса позволяет переоценить вероятность гипотезы (события) при поступлении новых данных (свидетельств). Она широко используется в машинном обучении, фильтрации спама и диагностике. Формула выводится из определения условной вероятности.
4. Метрики качества в задачах регрессии
Метрики регрессии оценивают, насколько предсказания модели близки к реальным значениям.
MSE (Среднеквадратическая ошибка)
MSE = (1/n) * Σ(y_pred - y_true)². Возведение ошибок в квадрат делает метрику чувствительной к большим отклонениям (выбросам), что заставляет модель сильнее на них реагировать.
MAE (Средняя абсолютная ошибка)
MAE = (1/n) * Σ|y_pred - y_true|. В отличие от MSE, штрафует за ошибки линейно, поэтому менее чувствительна к выбросам. Выбор между MSE и MAE зависит от важности учета больших отклонений в конкретной задаче.
MAPE (Средняя абсолютная процентная ошибка)
MAPE = (1/n) * Σ|(y_true - y_pred)/y_true| * 100%. Выражает ошибку в процентах от фактических значений, что удобно для интерпретации. Однако метрика нестабильна при значениях y_true, близких к нулю.
5. Метрики качества в задачах классификации
Метрики классификации оценивают способность модели правильно определять классы объектов.
Accuracy (Точность)
Доля правильных предсказаний среди всех: Accuracy = (TP+TN)/(TP+TN+FP+FN). Простая и интуитивная метрика, но она может вводить в заблуждение при несбалансированных классах.
Precision (Точность) и Recall (Полнота)
Precision (P) = TP / (TP + FP). Показывает, какая доля объектов, предсказанных как положительные, действительно является положительными.
Recall (R) = TP / (TP + FN). Показывает, какая доля реальных положительных объектов была правильно идентифицирована.
F-мера (F1-score)
Гармоническое среднее между Precision и Recall: F1 = 2 * (P * R) / (P + R). Позволяет найти баланс между двумя метриками, что особенно важно при дисбалансе классов.
Log Loss (Логарифмическая потеря)
Log Loss = - (1/n) * Σ [y_i * log(ŷ_i) + (1 - y_i) * log(1 - ŷ_i)]. Штрафует за уверенность модели в неправильном ответе. Чем меньше значение, тем лучше качество модели, особенно для вероятностных предсказаний.
Lift (Прирост)
Lift = Precision / (Доля положительных в выборке). Показывает, во сколько раз модель улучшает концентрацию положительных объектов в выбранной группе по сравнению со случайным выбором.
ROC-AUC
Площадь под ROC-кривой (Receiver Operating Characteristic). Кривая строится по точкам (FPR, TPR) при изменении порога классификации.
TPR (True Positive Rate) = Recall = TP / (TP + FN).
FPR (False Positive Rate) = FP / (FP + TN).
AUC показывает вероятность того, что случайно выбранный положительный объект получит оценку выше, чем случайно выбранный отрицательный. Значение от 0.5 (случайный классификатор) до 1 (идеальный).
PR-кривая (Precision-Recall)
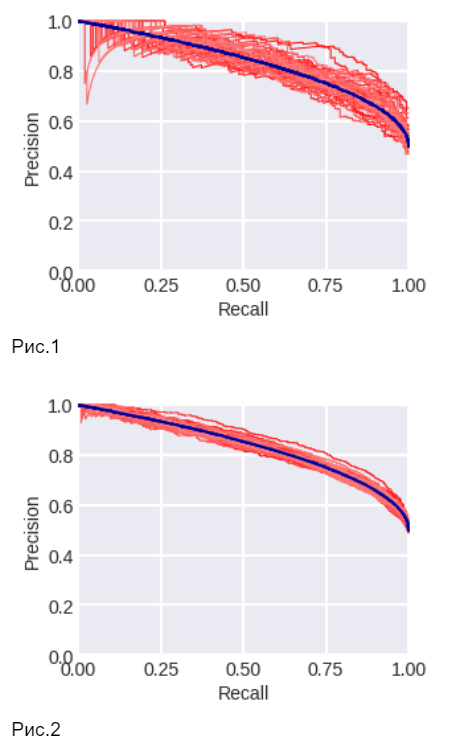
Строится в координатах Precision (по вертикали) и Recall (по горизонтали). Площадь под PR-кривой (PR-AUC) — альтернативная метрика, особенно информативная при сильном дисбалансе классов, когда положительных примеров мало. В отличие от ROC-AUC, она фокусируется на качестве предсказания именно положительного класса.
Это первая часть обширной шпаргалки для Data Scientist. Освоение этих базовых концепций — важный шаг к эффективной работе с данными.
Если материал был полезен, поддержите автора. Продолжение следует...
Стоит еще зайти сюда: Новости науки и техники.
Источник статьи: Большая шпаргалка Data Scientist'а (Часть 1).