
Эта подборка фундаментальных концепций составлена на основе многолетнего опыта и педагогической деятельности доктора философии Бенджамина Оби Тайо. Комментарии автора данной статьи выделены [в квадратных скобках].

1. Набор данных (Dataset)
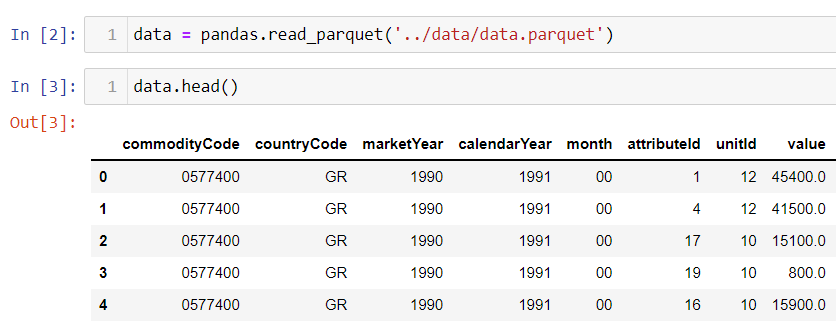
На изображении представлен пример набора данных о рынке сельскохозяйственной продукции с сайта Министерства сельского хозяйства США.
Сердце Data Science — это работа с данными. Набор данных представляет собой конкретную коллекцию информации, предназначенную для анализа или обучения моделей машинного обучения. Данные могут быть представлены в различных формах: числовые значения, категориальные признаки, текст, изображения, аудио и видео. Наборы данных могут быть статическими (неизменными) или динамическими (меняющимися во времени, как, например, биржевые котировки). Кроме того, данные часто зависят от географического контекста — показатели температуры в США и Африке будут кардинально различаться. Для начинающих наиболее распространенным и удобным форматом является CSV-файл с числовыми данными, [хотя в профессиональной среде набирает популярность формат Parquet, который обеспечивает эффективное сжатие и высокую скорость обработки в библиотеках типа pandas].
2. Предобработка данных (Data Wrangling)
Предобработка данных — это критически важный этап, на котором "сырые" и неструктурированные данные преобразуются в чистый и пригодный для анализа формат. Этот процесс включает в себя целый комплекс задач:
- Импорт данных из различных источников.
- Очистка данных от ошибок и аномалий.
- Структурирование и приведение к единому формату.
- Обработка текстовых строк.
- Парсинг HTML-кода.
- Работа с датами и временем.
- Заполнение или удаление пропущенных значений.
- Текстовый анализ (Text Mining).
В реальных проектах данные редко лежат в идеальном виде. Чаще всего их приходится извлекать из баз данных, PDF-документов, веб-страниц или социальных сетей. Умение грамотно предобрабатывать данные — ключевой навык, который позволяет раскрыть скрытые в информации закономерности и insights.
3. Визуализация данных (Data Visualization)
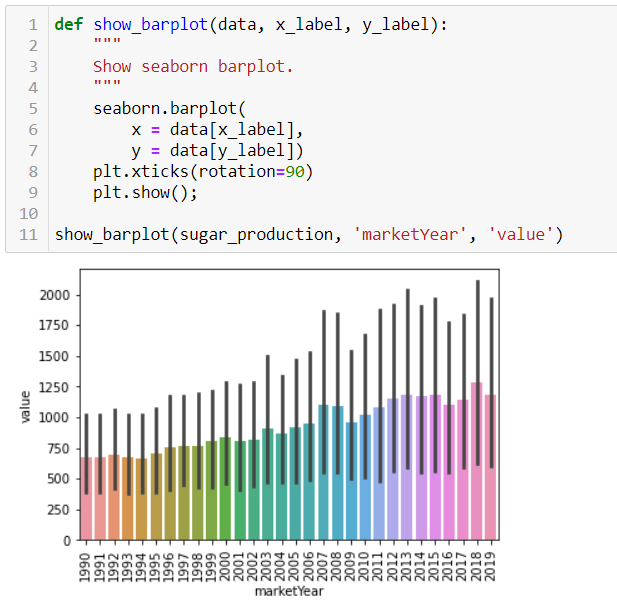
На графике показано распределение ключевого показателя по годам — это наглядный пример визуализации.
Визуализация данных — это мощный инструмент для исследования, анализа и коммуникации. С помощью графиков (точечных диаграмм, линейных графиков, гистограмм, тепловых карт и др.) можно проводить описательный анализ, выявлять взаимосвязи и тренды. В машинном обучении визуализация используется на всех этапах: от первичного анализа данных и отбора признаков до оценки качества построенной модели. Стоит помнить, что создание эффективной визуализации — это в большей степени искусство, чем точная наука. Часто для достижения отличного результата требуется комбинирование различных техник и инструментов.
4. Выбросы (Outliers)
Выбросы — это точки данных, которые значительно отклоняются от общей картины распределения. Они могут возникать из-за технических сбоев (неисправный датчик), человеческих ошибок при вводе или быть индикатором реального, но редкого события (например, сбой в системе). В больших наборах данных выбросы — обычное явление. Для их обнаружения часто используют диаграммы размаха (box plots).
На представленной прямоугольной диаграмме (box plot) отчетливо видны точки, выходящие за пределы "усов" — это и есть выбросы.
Выбросы могут серьезно искажать результаты анализа и ухудшать качество моделей машинного обучения. Самый простой способ борьбы с ними — удаление. Однако это не всегда оправдано, так как может привести к потере важной информации и созданию нереалистичных, излишне оптимистичных моделей.
5. Импутация данных (Data Imputation)
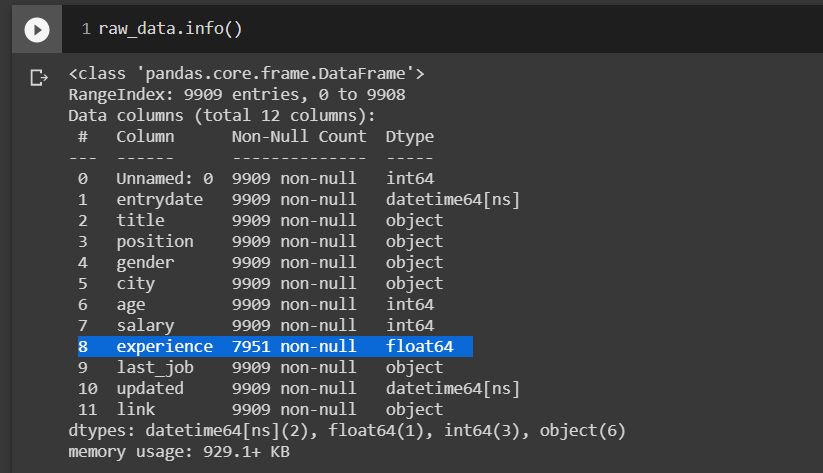
На изображении видно, что в столбце "experience" (опыт) данных значительно меньше, чем в других столбцах таблицы.
Пропущенные значения — частая проблема в реальных данных. Удаление всех строк с пропусками — не лучшее решение, так как это ведет к потере информации. Альтернатива — импутация, то есть заполнение пропусков оцененными значениями. Самый простой метод — замена пропуска средним значением по столбцу. Также можно использовать медиану или моду (наиболее частое значение).
По теме: MIT: ядерная энергия является неотъемлемой частью будущего энергетики с низким содержанием углерода.
Важно понимать, что любая импутация — это приближение, которое вносит погрешность в модель. При работе с уже предобработанными данными полезно выяснить, как именно обрабатывались пропуски: какой процент данных был удален и какие методы импутации применялись.6. Масштабирование признаков (Feature Scaling)
Масштабирование признаков — это приведение всех переменных к сопоставимому диапазону значений. Это необходимо, чтобы признаки с большим размахом (например, годовой доход в долларах) не доминировали над признаками с меньшим размахом (например, кредитный рейтинг от 0 до 850). Без масштабирования модель может стать смещенной и учитывать только "сильные" признаки.
Основные методы масштабирования — нормализация (MinMaxScaler, приводит значения к диапазону, например, [0, 1]) и стандартизация (StandardScaler, приводит данные к распределению с нулевым средним и единичной дисперсией). Выбор метода зависит от распределения данных: для равномерного распределения подходит нормализация, для нормального (гауссова) — стандартизация. Как и импутация, масштабирование является приближением и влияет на общую ошибку модели.
7. Метод главных компонент (PCA)
В наборах данных с сотнями признаков часто встречается избыточность и мультиколлинеарность (корреляция между признаками). Это может привести к переобучению модели и сложностям в интерпретации. Метод главных компонент (PCA) — это техника уменьшения размерности, которая преобразует исходные коррелированные признаки в новый набор некоррелированных переменных — главных компонент.
- PCA сокращает количество признаков, оставляя только те компоненты, которые объясняют большую часть дисперсии (изменчивости) данных.
- Метод устраняет корреляцию между исходными признаками.
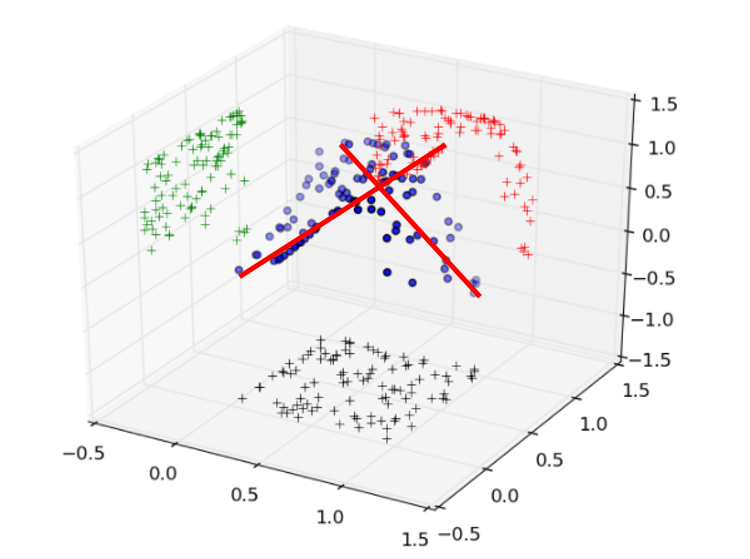
[Простой пример: представьте облако точек в трехмерном пространстве. Первая главная компонента — это направление, вдоль которого данные имеют наибольший разброс (максимальную дисперсию). Вторая компонента выбирается перпендикулярно первой, также максимизируя оставшуюся дисперсию, и так далее.]
8. Линейный дискриминантный анализ (LDA)
И PCA, и LDA — это методы линейного преобразования для снижения размерности данных. Однако у них разные цели. PCA — это алгоритм обучения без учителя (unsupervised), который ищет направления максимальной дисперсии во всем наборе данных, игнорируя метки классов. LDA — это алгоритм обучения с учителем (supervised), который целенаправленно ищет такое подпространство признаков, которое бы максимально разделяло заранее заданные классы объектов. Таким образом, LDA оптимизирует не дисперсию, а разделимость.
9. Разделение данных на выборки (Data Partitioning)
Одна из ключевых практик в машинном обучении — разделение исходного набора данных на обучающую (train) и тестовую (test) выборки. Модель обучается на обучающих данных, а ее реальная способность к обобщению (generalization error) проверяется на независимых тестовых данных, которые модель "не видела" во время обучения. Это позволяет оценить, как модель будет работать на новых, реальных данных. В библиотеке scikit-learn для этого используется функция `train_test_split`:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Здесь X — матрица признаков, y — целевая переменная. В примере тестовая выборка составляет 30% от всех данных.
10. Обучение с учителем (Supervised Learning)
Это самый распространенный тип машинного обучения, при котором алгоритм обучается на размеченных данных, то есть на примерах, для которых известен правильный ответ (целевая переменная). Задача алгоритма — выучить взаимосвязь между признаками (features) и целевой переменной (target). Обучение с учителем делится на две основные задачи:
а) Регрессия (Regression) — прогнозирование непрерывной числовой величины. Примеры алгоритмов: Линейная регрессия, K-ближайших соседей для регрессии (KNR), Регрессия опорных векторов (SVR).
б) Классификация (Classification) — предсказание дискретной метки класса. Примеры алгоритмов:
- Перцептрон
- Логистическая регрессия
- Метод опорных векторов (SVM)
- Дерево решений
- K-ближайших соседей (KNN)
- Наивный байесовский классификатор
Если материал оказался для вас полезным, поддержите автора лайком и подпиской на раздел.
Продолжение следует...
Стоит еще зайти сюда: Новости науки и техники.
Источник статьи: Топ-20 обязательных концепций Data Science для начинающих (Часть 1).