
Перечень концепций является результатом переосмысления Benjamin Obi Tayo Ph.D. своего многолетнего опыта в науке о данных. Также он ведет педагогическую деятельность и является писателем. Комментарии автора статьи [заключены в скобки].

1. Набор данных (Dataset)
 Набор данных о рынке сельхозпродукции с сайта МСХ США.
Набор данных о рынке сельхозпродукции с сайта МСХ США.В самом названии "Наука о данных" предполагается, что применяются некие научные методы с целью поиска закономерностей в наборах данных. Набор данных - это конкретный экземпляр данных, который используется для анализа или построения модели машинного обучения. Данные бывают числового типа, категориальные данные, текстовые данные, изображения, аудиозаписи и видео. Набор данных может быть статическим, или динамическим (изменяется со временем, например, цены на акции). Более того, набор данных также может зависеть от места. Например, данные о температуре в Соединенных Штатах будут значительно отличаться от данных о температуре в Африке. Для проектов начального уровня наиболее популярным типом наборов данных является набор данных, содержащий числовые данные, которые обычно хранятся в формате ".CSV" [однако в последнее время набирает популярность формат данных ".parquet", который удобен в работе, хорошо и быстро сжимает данные, поддерживается pandas].
2. Обработка данных (Data Wrangling)
Обработка данных - это процесс преобразования данных из необработанной формы в форму, готовую для анализа. Обработка данных является важным этапом предварительной подготовки и включает в себя несколько процессов, таких как:
- импорт данных,
- очистка данных,
- структурирование данных,
- обработка строк,
- синтаксический анализ HTML,
- обработка дат и времени,
- обработка недостающих данных,
- интеллектуальный анализ текста.
Процесс обработки данных - важный шаг для любого специалиста по данным. Очень редко данные в проектах легко доступны для анализа. Более вероятно, что данные будут в файле, базе данных, или извлечены из таких документов, как веб-страницы, твиты или PDF-файлы. Знание того, как обрабатывать и очищать данные, позволит вам извлекать из ваших данных важную информацию, которая в противном случае была бы скрыта.
3. Визуализация данных (Data Visualization)
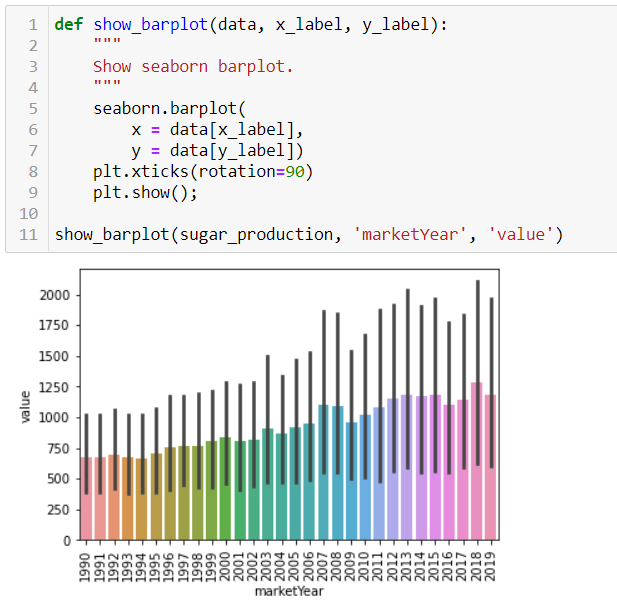 Распределение показателя по годам.
Распределение показателя по годам.Визуализация данных - одна из важнейших областей науки о данных. Это один из основных инструментов, используемых для анализа и изучения взаимосвязей между различными переменными. Визуализация данных (например, точечные диаграммы / scatter plots, линейные диаграммы / line graphs, гистограммы / bar plots, тепловые карты / heat maps и т. д.) могут использоваться для описательной аналитики. Визуализация данных также используется в машинном обучении для предварительной обработки и анализа данных, выбора функций, построения модели, тестирования модели и оценки модели. При подготовке визуализации данных имейте в виду, что визуализация данных - это больше искусство, чем наука. Чтобы получить хорошую визуализацию, вам нужно собрать несколько фрагментов кода для получения отличного конечного результата.
Пример построения визуализации.
4. Выбросы (Outliers)
Выброс - это точка данных, которая сильно отличается от остальной части набора данных. Выбросы часто являются просто неверными данными, например, из-за неисправного датчика; загрязненные эксперименты; или человеческая ошибка при записи данных. Иногда выбросы могут указывать на что-то реальное, например на неисправность в системе. Выбросы очень распространены и ожидаются в больших наборах данных. Один из распространенных способов обнаружения выбросов в наборе данных - использование прямоугольной диаграммы / box plot.
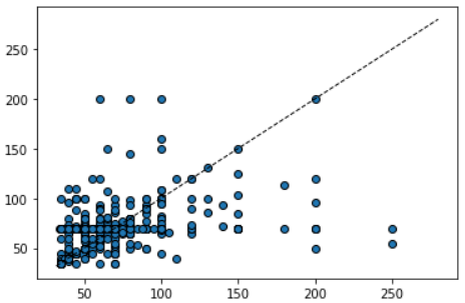 На прямоугольной диаграмме явно видны "нетиповые" точки.
На прямоугольной диаграмме явно видны "нетиповые" точки.Выбросы могут значительно ухудшить предсказательную способность модели машинного обучения. Обычный способ справиться с выбросами - просто опустить точки данных. Однако удаление выбросов из реальных данных может быть слишком оптимистичным, что приведет к нереалистичным моделям.
5. Вменение данных (Data Imputation)
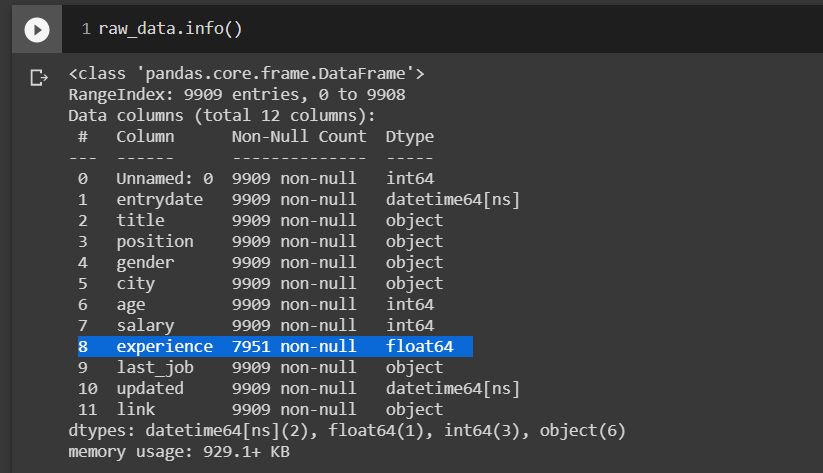 В столбце experience - явно меньше данных, чем в прочих столбцах.
В столбце experience - явно меньше данных, чем в прочих столбцах.Большинство наборов данных содержат пропущенные значения. Самый простой способ справиться с отсутствующими данными - просто исключить строку из таблицы, в которой есть пропуск. Однако удаление всех выборок просто невозможно, потому что мы можем потерять слишком много ценных данных. В этом случае мы можем использовать различные методы интерполяции для оценки недостающих значений из других обучающих выборок в нашем наборе данных. Одним из наиболее распространенных методов интерполяции является вменение среднего значения, при котором мы просто заменяем отсутствующее значение средним значением всего столбца признаков.
По теме: MIT: ядерная энергия является неотъемлемой частью будущего энергетики с низким содержанием углерода.
Другими вариантами для вменения пропущенных значений являются медиана или мода. Какой бы метод вменения вы ни использовали в своей модели, вы должны иметь в виду, что вменение является только приближением и, следовательно, может привести к ошибке в окончательной модели. Если предоставленные данные уже были предварительно обработаны, вам нужно будет выяснить, как учитывались пропущенные значения. Какой процент исходных данных был отброшен? Какой метод вменения использовался для оценки пропущенных значений?6. Масштабирование данных (Data Scaling)
Масштабирование ваших признаков (features) поможет улучшить качество и предсказательную силу вашей модели. Например, предположим, что вы хотите построить модель для прогнозирования кредитоспособности на основе переменных, таких как доход и кредитный рейтинг. Поскольку кредитные рейтинги варьируются от 0 до 850, а годовой доход может колебаться от 25 000 до 500 000 долларов США, без масштабирования ваших признаков модель будет смещена в сторону характеристики дохода. Это означает, что прогнозная модель будет прогнозировать кредитоспособность на основе только параметра дохода.
Чтобы привести функции к одному и тому же масштабу, мы могли бы решить использовать либо нормализацию, либо стандартизацию признаков. Чаще всего мы предполагаем, что данные распространяются нормально и по умолчанию используем стандартизацию, но это не всегда так. Перед использованием стандартизации или нормализации стоит посмотреть, как ваши признаки распределены статистически. Если признак имеет тенденцию к равномерному распределению, мы можем использовать нормализацию (MinMaxScaler). Если признак имеет гауссово распределение, то мы можем использовать стандартизацию (StandardScaler). Опять же, обратите внимание, что независимо от того, используете ли вы нормализацию или стандартизацию, это также приблизительные методы и обязательно вносят вклад в общую ошибку модели.
7. Анализ главных компонент (PCA)
Большие наборы данных с сотнями или тысячами объектов часто приводят к избыточности, особенно когда объекты коррелированы друг с другом. Обучение модели на наборе данных большой размерности, имеющем слишком много признаков, иногда может привести к переобучению (модель фиксирует как реальные, так и случайные эффекты). Кроме того, слишком сложную модель, имеющую слишком много признаков, может быть трудно интерпретировать. Одним из способов решения проблемы избыточности является использование методов выбора признаков и уменьшения размерности, таких как PCA. Анализ главных компонент (PCA) - это статистический метод, который используется для извлечения признаков. PCA используется для многомерных и коррелированных данных. Основная идея PCA - преобразовать исходное пространство признаков в пространство главного компонента. Преобразование PCA обеспечивает следующее:
- Уменьшение количества признаков, которые будут использоваться в окончательной модели, сосредоточив внимание только на компонентах, на которые приходится большая часть дисперсии в наборе данных.
- Исключение корреляции между признаками.
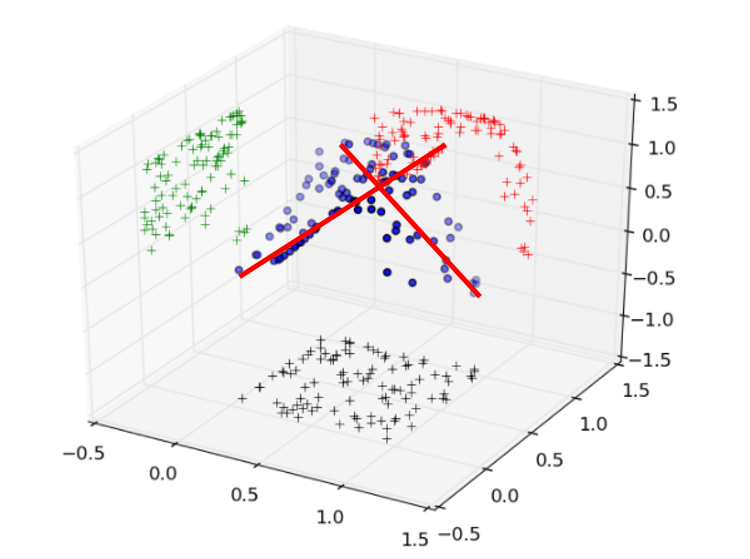
[Представьте, что в трехмерном пространстве у вас есть некое облако точек данных. Для нахождения первой главной компоненты нужно провести линию, которая пройдет через облако и будет иметь максимальную длину. Вторая главная компонента будет перпендикулярна первой, и пройдет через облако так, чтобы также максимизировать свою длину. И так далее.]
8. Линейный дискриминантный анализ (LDA)
PCA и LDA - это два метода линейного преобразования предварительной обработки данных, которые часто используются для уменьшения размерности для выбора соответствующих признаков, которые могут быть использованы в окончательном алгоритме машинного обучения. PCA - это неконтролируемый алгоритм (без учителя), который используется для извлечения признаков из высокоразмерных и коррелированных данных. PCA обеспечивает снижение размерности путем преобразования пространственных объектов в оси ортогональных компонентов с максимальной дисперсией в наборе данных. Цель LDA - найти подпространство признаков, которое оптимизирует разделимость классов и снижает размерность. Следовательно, LDA - это контролируемый алгоритм.
9. Разделение данных (Data Partitioning)
В машинном обучении набор данных часто разделяется на наборы для обучения и тестирования. Модель обучается на обучающем наборе данных, а затем тестируется на тестовом наборе данных. Таким образом, набор тестовых данных действует как невидимый набор данных, который можно использовать для оценки ошибки обобщения (ошибки, ожидаемой при применении модели к реальному набору данных после развертывания модели). В scikit-learn для разделения наборов можно использовать:
X_train, X_test, y_train, y_test = train_test_split (X, y, test_size = 0,3)
Здесь X - матрица признаков, а y - целевая переменная. В представленном примере тестовый набор данных составит 30% от общего набора.
10. Обучение с учителем (Supervised Learning)
Это алгоритмы машинного обучения, которые выполняют обучение, изучая взаимосвязь между переменными (признаками в данных) и известной целевой переменной. Контролируемое обучение делится на две подкатегории:
а) Непрерывные целевые переменные
Алгоритмы прогнозирования непрерывных целевых переменных включают линейную регрессию, метод ближайших соседей (KNR) и регрессию опорных векторов (SVR).
б) Дискретные целевые переменные
Алгоритмы прогнозирования дискретных целевых переменных включают:
- Классификатор перцептронов,
- Классификатор логистической регрессии,
- Машины опорных векторов (SVM),
- Классификатор дерева решений,
- Классификатор ближайших соседей,
- Наивный байесовский классификатор.
Если материал вам понравился и / или был полезен, подписывайтесь в раздел. Также не забывайте поощрять авторов лайками.
Продолжение следует...
Стоит еще зайти сюда: Новости науки и техники.
Источник статьи: Топ-20 обязательных концепций Data Science для начинающих (Часть 1).