
В материале собраны самые частые вопросы науки о данных, которые позволят поддерживать в актуальном состоянии понимание используемых концепций и технологий в этой сфере.

1. SQL для создания аналитических запросов к данным
Задача на поиск сотрудников в базе данных, получающих зарплату выше, чем у непосредственного руководителя:
SELECT *
FROM employee AS a, employee AS b
WHERE b.id = a.chief_id
AND a.salary > b.salary
;
Задача на поиск самого большого значения заработной платы, не равное максимальной заработной плате полученной по всей таблице:
-- Выбираем максимальное значение
SELECT MAX ( salary ) AS NextMaxSalary
FROM employee
-- не равное максимальному значению
WHERE SALARY !=
( SELECT MAX ( salary )
FROM employee
)
;
Задача на нумерацию строк в таблице в разрезе департамента по зарплате:
SELECT ROW_NUMBER ()
over (
PARTITION BY department ORDER BY salary
)
AS salary_num
FROM employee
;
2. Математическая статистика
Математическое ожидание
M [ x ] означает среднее значение случайной величины:
xi | 1 | 3 | 4 | 7
pi | 0.1 | 0.1 | 0.2 | 0.3
M [ x ] = 1 * 0.1 + 3 * 0.1 + 4 * 0.2 + 7 * 0.3 = 3.3
Медиана
Медиана это квантиль порядка 0.5 Такое число, которое находится посередине, когда мы расписываем наши числа в порядке возрастания. Если чисел в ряду четное количество, то медиана - это среднее двух элементов, расположенных посередине.
Квантиль
Значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Например, квантиль 0.25 - число, ниже которого лежит примерно 25% выборки.
Мода
Самое вероятное значение случайной величины. В списке 4, 4, 3, 5 - мода = 4.
Бимодальное распределение
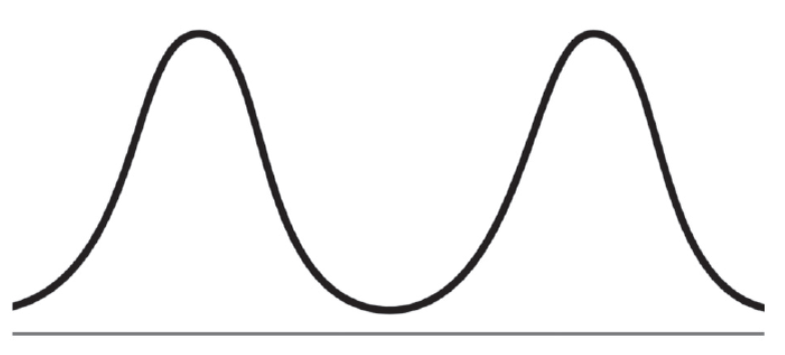 Бимодальное распределение.
Бимодальное распределение.У распределения может быть два и более пиков. Средние значения ничего не скажут в таком распределении. Целесообразно разделить такие выборки по подгруппам, анализировать их.
Дисперсия и СКО
Дисперсия - это мера разброса значения случайной величины относительно ее математического ожидания.
D(X) = M ( X - M(X) ) ^ 2
СКО - среднеквадратическое отклонение - это корень квадратный из D(X). На практике среднеквадратическое отклонение позволяет оценить, насколько значения из множества могут отличаться от среднего значения.
Интерквантильный размах
IQR = X 0.75 - X 0.25. Это разность квантилей заданного порядка.
3. Теория вероятности
Пересечение событий ( ∩ )
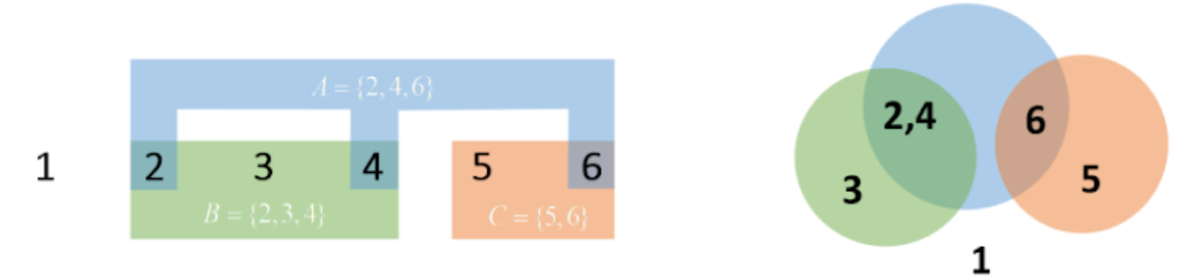
Пусть есть возможные исходы {1, 2, 3, 4, 5, 6}. События A {2, 4, 6}, B {2, 3, 4}, C {5, 6}. Пересечение состоит из тех исходов, которые принадлежат каждому событию. Например, пересечение событий A ∩ B = {2, 4}.
Объединение событий ( ∪ )
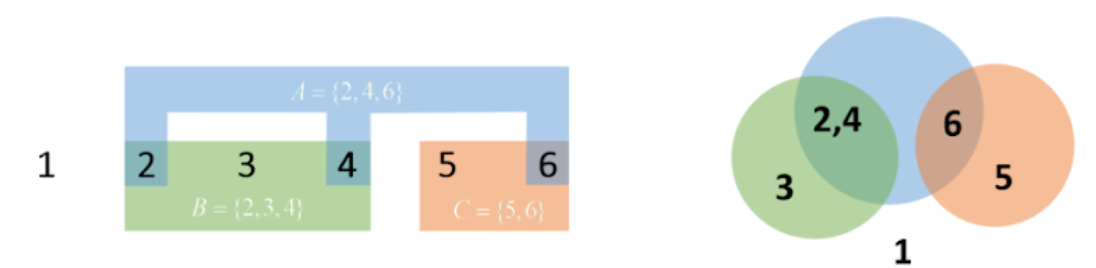
Пусть есть возможные исходы {1, 2, 3, 4, 5, 6}. События A {2, 4, 6}, B {2, 3, 4}, C {5, 6}. Объединение состоит состоит из тех исходов, которые принадлежат хотя бы одному событию. Например, объединение событий A ∪ B = {2, 3, 4, 6}.
Условная вероятность
Это вероятность события, если известно, что другое событие произошло:
P( A | B ) = P(A ⋂ B) / P( B ), где B - условие, которое произошло.
Взаимоисключающие события
Взаимоисключающие события - которые не пересекаются. Произошло одно - НЕ произошло другое. Тогда разбиение - это набор взаимоисключающих и совместно исчерпывающих событий → Полная вероятность. Это означает, что события не пересекаются и при этом дают все возможные исходы. P = 1
Теорема Байеса
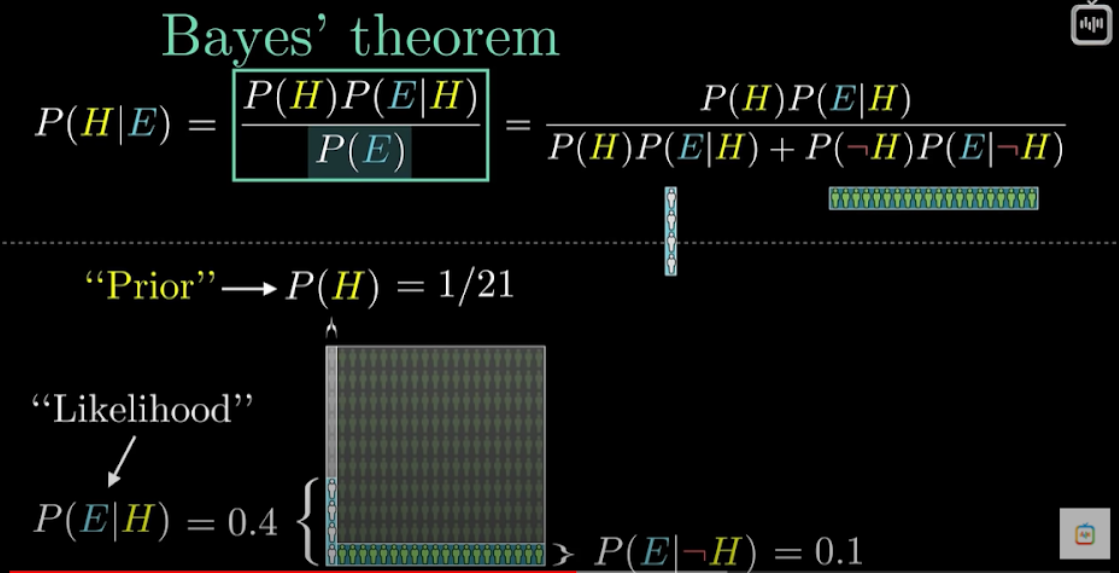 Из видео сайта VertDider.
Из видео сайта VertDider.Наглядная визуализация работы теоремы Байеса по ссылке.
4. Метрики качества в задачах регрессии
MSE
Среднеквадратическая ошибка. Данная метрика повышает эффективность обучения модели за счет того, что ошибки возводятся в квадрат и модель “усиленно” штрафуется.
SUM ( ( y_pred - y_true ) ^ 2 )
MAE
Cредняя абсолютная ошибка. Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам.
По теме: MIT: ядерная энергия является неотъемлемой частью будущего энергетики с низким содержанием углерода.
При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.SUM | y_pred - y_true |
MAPE
Средняя абсолютная процентная ошибка. Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений. Основная проблема данной ошибки — нестабильность [Подробнее].
5. Метрики качества в задачах классификации
Accuracy
Доля правильных ответов. Хорошо применима для демонстрации результата работы модели для бизнеса, т.к. показатель хорошо воспринимается интуитивно. Условие - выборка должна быть сбалансирована.
Presicion
Точность. Показывает, насколько можно доверять классификатору в случае срабатывания.
P = ( TP ) / ( TP + FP )
Recall
Полнота. Показывает, на какой доле истинных ответов алгоритм срабатывает.
R = ( TP ) / ( TP + FN ) - в знаменателе все истинные позитивные
F-мера
В случае, если выборка не сбалансирована, то необходимо учитывать это. F-мера рассчитывается как F = ( 2 * P * R ) / ( P + R ) и учитывает разбалансированность точности и полноты.
Logloss
Логарифмическая функция потерь. y^ - это ответ алгоритма на i-м объекте, y - истинная метка класса на i-м объекте, l - размер выборки. l - необходим тогда, когда модель мультиклассовой классификации. При бинарной классификации - не используется. Очень сильно штрафует за неправильные ответы.
logloss = - 1 / l * SUM ( yi * log( y^ ) + ( 1 - yi ) * log( 1 - y^ ) )
Lift
Метрика прироста концентрации. Эту величину можно интерпретировать как улучшение доли положительных объектов в данном подмножестве относительно доли в случайно выбранном подмножестве такого же размера.
lift = Presicion / ( ( TP + FN ) / l )
ROC-AUC
Значение ROC-AUC имеет значение того, что если были выбраны случайный положительный и случайный отрицательный объекты выборки, положительный объект получит оценку принадлежности выше, чем отрицательный объект. Строится в осях True Positive Rate ( TPR ) и False Positive Rate ( FPR ).
TPR = TP / ( TP + FN )
FPR = FP / ( FP + TN )
PR-кривая
Эта кривая строится в координатах полнота (R = recall = ( TP ) / ( TP + FN )) и точность (P = precision = ( TP ) / ( TP + FP )).
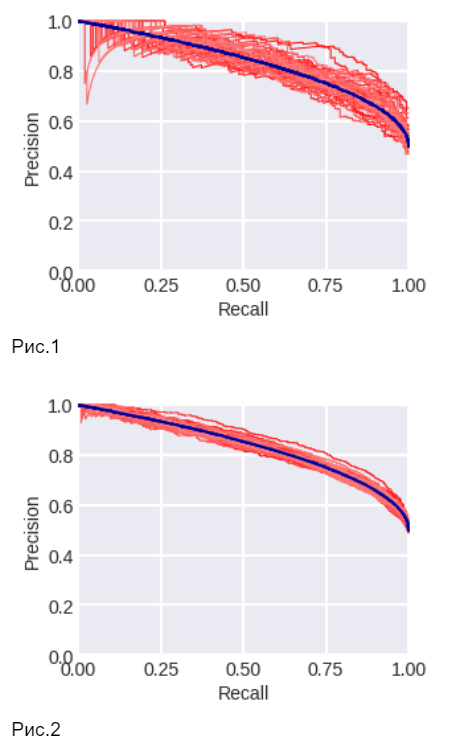
На рис. 1-2 показаны PR-кривые в модельной задаче: синим – теоретическая кривая, красными тонкими линиями – кривые, построенные по выборкам с соответствующими плотностями. Рис. 1 – для выборок из 300 объектов, рис. 2 – для выборок из 3000 объектов. Заметим, что в общем случае PR-кривая не выпуклая. Площадь под ней часто используют в качестве метрики качества алгоритма. В нашей теоретической задаче PR-площадь равна 5/6=0.8(3), для выборок из 300 объектов после 100 экспериментов (генераций выборок) её оценка равна 0.839 ± 0.024 (std), для выборок из 3000 – 0.833 ± 0.012 (std) [Подробнее].
Если материал вам понравился и / или был полезен, подписывайтесь в раздел. Также не забывайте поощрять авторов лайками.
Продолжение следует...
Стоит еще зайти сюда: Новости науки и техники.
Источник статьи: Большая шпаргалка Data Scientist'а (Часть 1).