
Перечень концепций является результатом переосмысления Benjamin Obi Tayo Ph.D. своего многолетнего опыта в науке о данных. Также он ведет педагогическую деятельность и является писателем. Комментарии автора статьи [заключены в скобки]. Продолжение первой части.
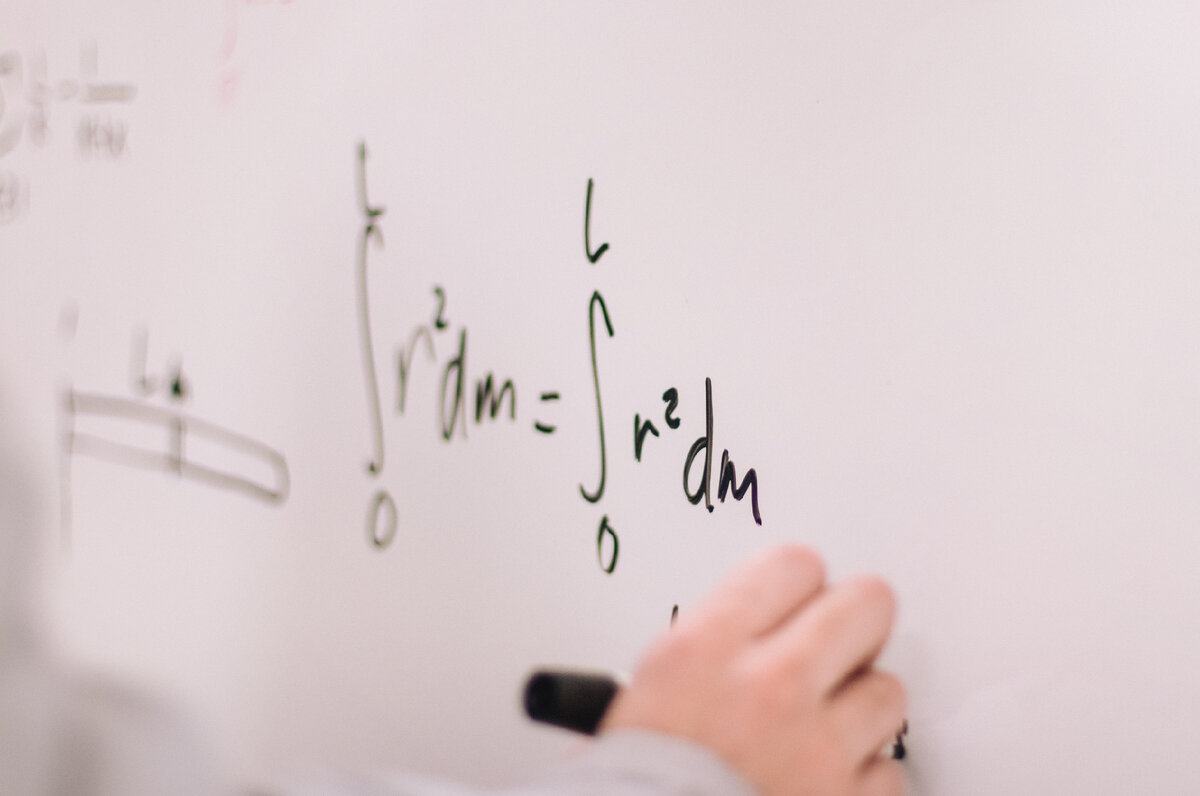
11. Обучение без учителя (Unsupervised Learning)
При обучении без учителя мы имеем дело с немаркированными данными или данными неизвестной структуры. Используя методы обучения без учителя, мы можем исследовать структуру наших данных для извлечения значимой информации без указания целевой переменной, или функции вознаграждения. Например, K-means является представителем алгоритма обучения без учителя.
 Визуализация результатов алгоритма K-means (K=4).
Визуализация результатов алгоритма K-means (K=4).[Алгоритм работает таким образом, что определяет ближайших соседей от случайно заданных центров выборки - K].
12. Обучение с подкреплением (Reinforcement Learning)
В обучении с подкреплением цель состоит в том, чтобы разработать систему (агента), которая улучшает свою эффективность на основе взаимодействия с окружающей средой. Поскольку информация о текущем состоянии окружающей среды обычно также включает в себя так называемый сигнал вознаграждения, мы можем рассматривать обучение с подкреплением как область обучения с учителем. Однако в обучении с подкреплением эта обратная связь не является признаком истинности, или значением, а является мерой того, насколько хорошо действие было измерено функцией вознаграждения. Взаимодействуя с окружающей средой, агент может затем использовать обучение с подкреплением, чтобы выучить серию действий, которые максимизируют эту награду.
[К примеру, модель, обученная с подкреплением, может управлять стабилизацией возвратной ступени Falcon от SpaceX в вертикальном положении при ее посадке, как бы "подруливая" двигателями для того, что бы получить вознаграждение - посадку ступени в заданных координатах.]
 Из видео компании SpaceX.
Из видео компании SpaceX.13. Параметры модели и гиперпараметры (Model Parameters and Hyperparameters)
В модели машинного обучения есть два типа параметров:
a) Параметры: это параметры модели, которые должны быть определены с использованием набора обучающих данных. Это подогнанные параметры. Например, предположим, что у нас есть такая модель:
Цена дома = a + b * (возраст) + c * (размер). a, b, c - параметры модели.
Чтобы оценить стоимость дома на основе его возраста и размера (квадратный метр), нужно сначала подобрать a, b, c путём обучения модели на обучающем наборе данных.
б) Гиперпараметры: это регулируемые параметры, которые необходимо настроить для получения модели с оптимальными характеристиками. Здесь показан пример гиперпараметра:
KNeighborsClassifier (n_neighbors = 5, p = 2, metric = 'minkowski')
Важно, чтобы во время обучения гиперпараметры были подобраны для получения модели с наилучшими характеристиками (с наиболее подходящими параметрами). Решение такой задачи - одна из обязанностей специалиста по данным.
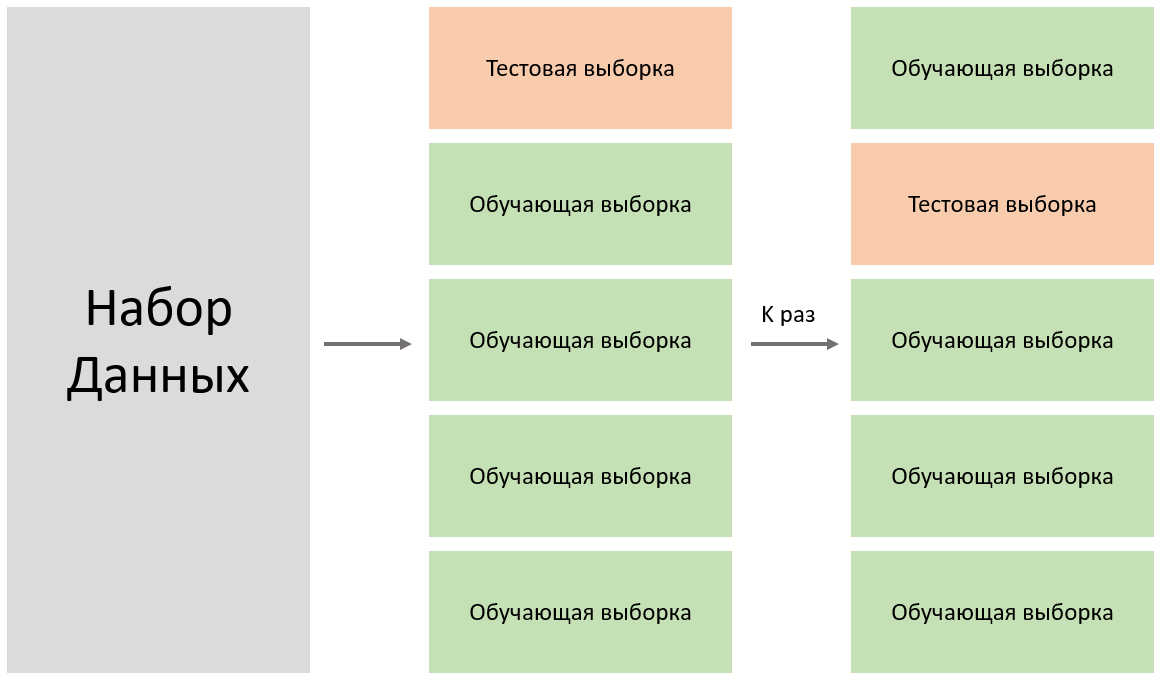
14. Перекрестная проверка (Cross-validation)
Перекрестная проверка - это метод оценки устойчивости модели машинного обучения на случайных выборках набора данных. Это гарантирует фиксацию любых смещений в наборе данных. Перекрестная проверка может помочь нам получить надежные оценки ошибки обобщения модели, то есть того, насколько хорошо модель работает с теми данными, которых она не видела ранее.
При k-кратной перекрестной проверке набор данных случайным образом разбивается на выборки для обучения и тестирования. Модель обучается на обучающем наборе и оценивается на тестовом наборе. Процесс повторяется k раз. Затем вычисляются средние оценки обучения и тестирования путем усреднения по k-кратным значениям.
15. Компромисс смещения и разброса (Bias-variance Tradeoff)
В статистике и машинном обучении компромисс между смещением и разбросом (дисперсией) является свойством набора прогнозных моделей, в соответствии с которым модели с более низким смещением в оценке параметров имеют более высокую дисперсию оценок параметров по выборкам и наоборот. Дилемма, или проблема смещения и дисперсии заключается в конфликте попыток одновременно минимизировать эти два источника ошибок, которые не позволяют алгоритмам машинного обучения с учителем обобщаться за пределы их обучающей выборки:
- Смещение - это ошибка из-за ошибочных предположений в алгоритме обучения.
По теме: MIT: ядерная энергия является неотъемлемой частью будущего энергетики с низким содержанием углерода.
Сильное смещение (слишком простая модель) может привести к тому, что алгоритм упустит релевантные отношения между признаками в данных и целевыми значениями (результат - недостаточная подгонка модели). - Дисперсия - это ошибка из-за чувствительности к небольшим колебаниям обучающей выборки. Высокая дисперсия (слишком сложная модель) может привести к тому, что алгоритм будет моделировать случайный шум в обучающих данных, а не истинные зависимости (результат - переобучение модели).
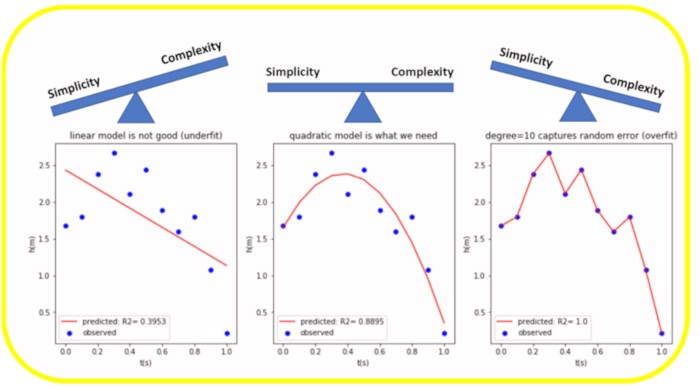 Идеальный вариант - по центру. Слева - смещение, справа - излишняя дисперсия. Изображение Benjamin O. Tayo.
Идеальный вариант - по центру. Слева - смещение, справа - излишняя дисперсия. Изображение Benjamin O. Tayo.16. Метрики оценки (Evaluation Metrics)
В машинном обучении (предиктивной аналитике) есть несколько метрик, которые можно использовать для оценки модели. Например, модель обучения с учителем (целевое значение - непрерывная величина) может быть оценена с использованием таких показателей, как оценка R2, среднеквадратичная ошибка (MSE) или средняя абсолютная ошибка (MAE). Кроме того, модель обучения с учителем (целевое значение - дискретная величина), также называемая моделью классификации, может быть оценена с использованием таких показателей, как тщательность (accuracy), точность (precision), полнота (recall), F-мера и площадь под кривой ROC (AUC).
17. Количественная оценка неопределенности (Uncertainty Quantification)
Важно создавать модели машинного обучения, которые будут давать объективные оценки неопределенностей в расчетных результатах. R2-мера, или коэффициент детерминации показывает ту долю разброса целевой переменной, которая объясняется объясняющими переменными, т.е. признаками набора данных (предикторами).
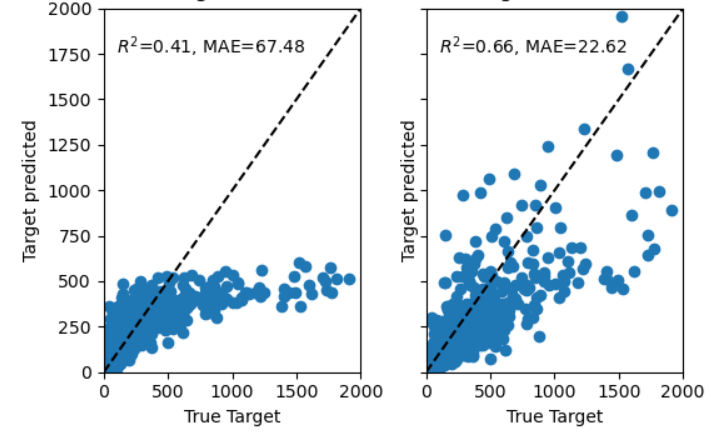 Пример применения R2 из библиотеки sklearn.
Пример применения R2 из библиотеки sklearn.[На графике справа R2 - выше, чем на графике слева. Это означает, что признаки в данных слева хуже объясняют целевую переменную (таргет). Зависимость носит более случайный характер.]
18. Математические концепции
a) Базовое исчисление: большинство моделей машинного обучения построены с использованием набора данных, имеющего несколько признаков (объясняющих переменных, предикторов). Следовательно, знакомство с многомерным исчислением чрезвычайно важно для построения модели машинного обучения. Вот темы, с которыми вам необходимо ознакомиться:
- Функции нескольких переменных;
- Производные и градиенты;
- Шаговая функция, сигмовидная функция, логит-функция, функция ReLU;
- Функция стоимости;
- Построение функций;
- Минимальные и максимальные значения функции.
б) Базовая линейная алгебра: линейная алгебра - самый важный математический навык в машинном обучении. Набор данных представлен в виде матрицы. Линейная алгебра используется при предварительной обработке данных, преобразовании данных, уменьшении размерности и оценке модели. Вот темы, с которыми вам необходимо ознакомиться:
- Векторы;
- Норма вектора;
- Матрицы;
- Транспонирование матриц;
- Обратная матрица;
- Определитель матрицы;
- След матрицы;
- Скалярное произведение;
- Собственные значения;
- Собственные векторы.
в) Методы оптимизации: большинство алгоритмов машинного обучения выполняют прогнозное моделирование, минимизируя целевую функцию, тем самым изучая веса, которые должны применяться к данным тестирования, чтобы получить предсказанные метки. Вот темы, с которыми вам необходимо ознакомиться:
- Функция затрат / целевая функция;
- Функция правдоподобия;
- Функция ошибки;
- Алгоритм градиентного спуска и его варианты (например, алгоритм стохастического градиентного спуска)
19. Статистика и теория вероятностей
Статистика и вероятность используются для визуализации признаков данных, предварительной обработки данных, преобразования признаков, вменения данных, уменьшения размерности, создания признаков, оценки модели и т. д. Вот темы, с которыми вам необходимо ознакомиться:
- Среднее значение, медиана, мода, стандартное отклонение / дисперсия;
- Коэффициент корреляции и матрица ковариаций;
- Распределения вероятностей (биномиальное, пуассоновское, нормальное);
- p-значение;
- Теорема Байеса (точность, полнота, положительное прогнозное значение, отрицательное прогнозное значение, матрица неточностей, Кривая ROC);
- Центральная предельная теорема;
- Оценка R2;
- Среднеквадратическая ошибка (MSE);
- A / B-тестирование;
- Моделирование Монте-Карло.
20. Инструменты для повышения производительности
Типичный проект анализа данных может включать несколько частей, каждая из которых включает несколько файлов данных и различные сценарии с кодом. Хранить все это в порядке может быть непросто. Инструменты повышения производительности помогут вам организовать проекты и вести учет выполненных проектов. Некоторые важные инструменты повышения производительности для практикующих специалистов по обработке данных включают такие инструменты, как:
- GNU Linux OS [ большинство приложений нативно под эту операционную систему ];
- git и GitHub [ для версионирования и хранения кода ];
- Jupyter Notebook / Jupyter Lab / Azure Data Studio [ для разведывательной аналитики ];
- DVC [ для контроля версий данных ];
- git и GitHub [ для версионирования и хранения кода];
- Flask [ для декорирования обученных моделей ];
- Docker [ для развертки моделей в продакшн-среде ].
Стоит еще зайти сюда: Новости науки и техники.
Источник статьи: Топ-20 обязательных концепций Data Science для начинающих (Часть 2).